![[Neural Network]](graphics/neuralnw.gif)
For more information, see Time Series.
N-in-One Encoding. For nominal variables with more than two states, the practice of representing the variable using a single unit with a range of possible values (actually implemented using minimax, explicit or none). See also, Neural Networks.
Neat Scaling of Intervals. The term neat scaling is used to refer to the manner in which ranges of values are divided into intervals, so that the resulting interval boundaries and steps between those boundaries are intuitive and readily interpretable (or "understood").
For example, suppose you want to create a histogram for data values in the range from 1 to 10. It would be inefficient to use interval boundaries for the histogram at values such as 1.3, 3.9, 6.5, etc., i.e., to use as a minimum boundary value 1.3, and then a step size of 2.6. A much more intuitive way to divide the range of data values would be to use boundaries like 1, 2, 3, 4, and so on, i.e., a minimum boundary at 1, with step size of 1; or one could use 2, 4, 6, etc, i.e., a minimum boundary of 2 and step size 2.
In general, neat in this context means that category boundaries will be round values ending either in 0, 2, or 5 (e.g., boundaries may be 0.1, 0.2, 0.3, etc.; or 50, 100, 150, etc.). To achieve this, any user-requested lower limit, upper limit, and number of categories will only be approximated.
Negative Correlation. The relationship between two variables is such that as one variable's values tend to increase, the other variable's values tend to decrease. This is represented by a negative correlation coefficient.
See also, Correlations - Introductory Overview.
Negative Exponential (2D graphs). A curve is fitted to the XY coordinate data according to the negative exponentially-weighted smoothing procedure (the influence of individual points decreases exponentially with the horizontal distance from the respective points on the curve).
Negative Exponential (3D graphs). A surface is fitted to the XYZ coordinate data according to the negative exponentially- weighted smoothing procedure (the influence of individual points decreases exponentially with the horizontal distance from the respective points on the surface).
Neighborhood (in Neural Networks). In Kohonen training, a square set of units focused around the "winning" unit and simultaneously updated by the training algorithm.
Nested Factors. In nested designs the levels of a factor are nested (the term was first used by Ganguli, 1941) within the levels of another factor. For example, if one were to administer four different tests to four high school classes (i.e., a between-groups factor with 4 levels), and two of those four classes are in high school A, whereas the other two classes are in high school B, then the levels of the first factor (4 different tests) would be nested in the second factor (2 different high schools).
See also, ANOVA/MANOVA.
Nested Sequence of Models. In Structural Equation Modeling, a set of models M(1), M(2), ... M(k) form a nested sequence if model M(i) is a special case of M(i+1) for i=1 to k-1. Thus, each model in the sequence becomes increasingly more general, but includes all previous models as special cases. As an example, consider one factor, two factor, and three factor models for 10 variables. The two factor model includes the one factor model as a special case (simply let all the loadings on the second factor be 0). Similarly, the three factor model contains the two and one factor models as special cases.
Neural Networks. Neural Networks are analytic techniques modeled after the (hypothesized) processes of learning in the cognitive system and the neurological functions of the brain and capable of predicting new observations (on specific variables) from other observations (on the same or other variables) after executing a process of so-called learning from existing data.
For more information, see Neural Networks; see also Data Mining, and STATISTICA Neural Networks.
Neuron. A unit in a neural network.
Newman-Keuls test. This post hoc test can be used to determine the significant differences between group means in an analysis of variance setting. The Newman-Keuls test, like Duncan's test, is based on the range statistic (for a detailed discussion of different post hoc tests, see Winer, Michels, & Brown (1991). For more details, see the General Linear Models chapter. See also, Post Hoc Comparisons. For a discussion of statistical significance, see Elementary Concepts.
Noise Addition (in Neural Networks). A practice (used in neural networks) designed to prevent overlearning during back propagation training, by adding random noise to input patterns during training (and so "blurring" the position of the training data). See, Neural Networks.
Nominal Scale. This is a categorical (i.e., quantative and not qualitative) scale of measurement where each value represents a specific category that the variable's values fall into (each category is "different" than the others but cannot be quantitatively compared to the others).
See also, Elementary Concepts.
Nominal Variables. Variables which take on one of a set of discrete values, such as Gender={Male, Female}. In neural networks, nominal output variables are used to distinguish classification tasks from regression tasks. See also, Grouping (or Coding) Variable and Measurement scales.
Nonlinear Estimation. In the most general terms, Nonlinear estimation involves finding the best fitting relationship between the values of a dependent variable and the values of a set of one or more independent variables (it is used as either a hypothesis testing or exploratory method). For example, we may want to compute the relationship between the dose of a drug and its effectiveness, the relationship between training and subsequent performance on a task, the relationship between the price of a house and the time it takes to sell it, etc. Research issues in these examples are commonly addressed by such techniques as multiple regression (see, Multiple Regression) or analysis of variance (see, ANOVA/MANOVA). In fact, one may think of Nonlinear estimation as a generalization of those methods. Specifically, multiple regression (and ANOVA) assumes that the relationship between the independent variable(s) and the dependent variable is linear in nature. Nonlinear Estimation leaves it up to you to specify the nature of the relationship; for example, you may specify the dependent variable to be a logarithmic function of the independent variable(s), an exponential function, a function of some complex ratio of independent measures, etc. (However, if all variables of interest are categorical in nature, or can be converted into categorical variables, you may also consider Correspondence Analysis as an alternative analysis technique.)
For more information, see the Nonlinear Estimation chapter.
Nonparametrics. Nonparametric methods were developed to be used in cases when the researcher does not know the parameters of the distribution of the variable of interest in the population (hence the name nonparametric). In more technical terms, nonparametric methods do not rely on the estimation of parameters (such as the mean or the standard deviation) describing the distribution of the variable of interest in the population. Therefore, these methods are also sometimes (and more appropriately) called parameter-free methods or distribution-free methods.
For more information, see the Nonparametrics Introductory chapter, see also Elementary Concepts.
Non-outlier range. The non-outlier range is the range of values in the 2D Box Plots, 3D Sequential Graphs - Box Plots, or Categorized Box Plots, which fall below the upper outlier limit (for example, +1.5 * the height of the box) and above the lower outlier limit (for example, -1.5 * the height of the box).
Nonseasonal, Damped Trend.
In this Time Series model, the simple exponential smoothing forecasts are "enhanced" by a damped trend component (independently smoothed with parameters 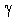 for the trend, and
for the trend, and 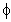 for the damping effect). For example, suppose we wanted to forecast from month to month the percentage of households that own a particular consumer electronics device (e.g., a VCR). Every year, the proportion of households owning a VCR will increase, however, this trend will be damped (i.e., the upward trend will slowly disappear) over time as the market becomes saturated.
for the damping effect). For example, suppose we wanted to forecast from month to month the percentage of households that own a particular consumer electronics device (e.g., a VCR). Every year, the proportion of households owning a VCR will increase, however, this trend will be damped (i.e., the upward trend will slowly disappear) over time as the market becomes saturated.
To compute the smoothed value (forecast) for the first observation in the series, both estimates of S0 and T0 (initial trend) are necessary. By default, these values are computed as:
T0 = (1/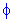 )*(Xn-X1)/(N-1)
)*(Xn-X1)/(N-1)
where
N is the number of cases in the series,
is the smoothing parameter for the damped trend
and S0 = X1-T0/2
Nonseasonal, Exponential Trend.
In this Time Series model, the simple exponential smoothing forecasts are "enhanced" by an exponential trend component (smoothed with parameter ). For example, suppose we wanted to predict the overall monthly costs of repairs to a production facility. There could be an exponential trend in the cost, that is, from year to year the costs of repairs may increase by a certain percentage or factor, resulting in a gradual exponential increase in the absolute dollar costs of repairs.
To compute the smoothed value (forecast) for the first observation in the series, both estimates of S0 and T0 (initial trend) are necessary. By default, these values are computed as:
T0 = (X2/X1)
and
S0 = X1/T01/2
Nonseasonal, Linear Trend.
In this Time Series model, the simple exponential smoothing forecasts are "enhanced" by a linear trend component that is smoothed independently via the (gamma) parameter (see discussion of trend smoothing parameters). This model is also referred to as Holt's two parameter method. This model would, for example, be adequate when producing forecasts for spare parts inventories. The need for particular spare parts may slowly increase or decrease over time (the trend component), and the trend may slowly change as different machines etc. age or become obsolete, thus affecting the trend in the demand for spare parts for the respective machines.
In order to compute the smoothed value (forecast) for the first observation in the series, both estimates of S0 and T0 (initial trend) are necessary. By default, these values are computed as:
T0 = (Xn-X1)/(N-1)
where
N is the length of the series,
and S0 = X1-T0/2
Nonseasonal, No Trend. This Time Series model is equivalent to the simple exponential smoothing model. Note that, by default, the first smoothed value will be computed based on an initial S0 value equal to the overall mean of the series.
Normal Distribution. The normal distribution (the term first used by Galton, 1889) function is determined by the following formula:
f(x) = 1/[2* )1/2*
)1/2* ] * e**{-1/2*[(x-µ)/]2}
] * e**{-1/2*[(x-µ)/]2}
- < x <
< x <
where
µ is the mean
is the standard deviation
e is the
base of the natural logarithm, sometimes called Euler's e (2.71...)
is the constant Pi (3.14...)
See also, Bivariate Normal Distribution, Elementary Concepts (Normal Distribution), Basic Statistics - Tests of Normality
Normal Fit. The normal/observed histogram represents the most common graphical test of normality. When you select this fit, a normal curve will be overlaid on the frequency distribution. The normal function fitted to histograms is defined as:
f(x) = NC * step * normal(x, mean, std.dev)
The normal function fitted to cumulative histograms is defined as:
f(x) = NC * inormal(x, mean, std.dev.)
where
NC is the number of cases.
step is the categorization step size
(e.g., the integral categorization step size is 1).
normal is the normal function.
inormal is the integral of the normal function.
See also, Normal Distribution, and Bivariate Normal Distribution.
Normal Probability Plots (Computation Note). The following formulas are used to convert the ranks into expected normal probability values, that is, the respective normal z values.
Normal probability plot. The normal probability value zj for the jth value (rank) in a variable with N observations is computed as:
z j =  -1 [(3*j-1)/(3*N+1)]
-1 [(3*j-1)/(3*N+1)]
where -1 is the inverse normal cumulative distribution function (converting the normal probability p into the normal value z).
Half-normal probability plot. Here, the half-normal probability value zj for the jth value (rank) in a variable with N observations is computed as:
z j = -1 [3*N+3*j-1)/(6*N+1)]
where -1 is again the inverse normal cumulative distribution function.
Detrended normal probability plot. In this plot each value (xj) is standardized by subtracting the mean and dividing by the respective standard deviation (s). The detrended normal probability value zj for the jth value (rank) in a variable with N observations is computed as:
z j = -1 [(3*j-1)/(3*N+1)] - (x j-mean)/s
where -1 is again the inverse normal cumulative distribution function.
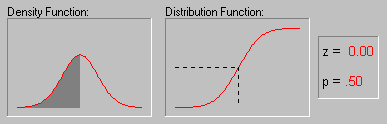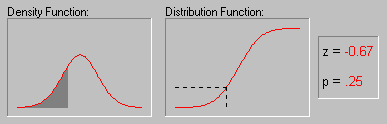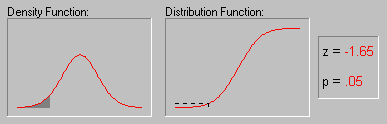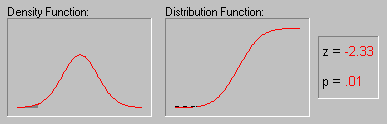
Normal Probability Plots. This type of graph is used to evaluate the normality of the distribution of a variable, that is, whether and to what extent the distribution of the variable follows the normal distribution. The selected variable will be plotted in a scatterplot against the values "expected from the normal distribution."
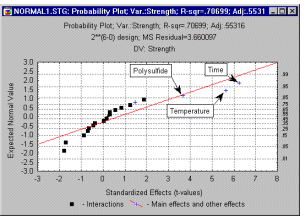
The standard normal probability plot is constructed as follows. First, the deviations from the mean (residuals) are rank ordered. From these ranks the program computes z values (i.e., standardized values of the normal distribution) based on the assumption that the data come from a normal distribution (see Computation Note). These z values are plotted on the Y-axis in the plot. If the observed residuals (plotted on the X-axis) are normally distributed, then all values should fall onto a straight line. If the residuals are not normally distributed, then they will deviate from the line. Outliers may also become evident in this plot. If there is a general lack of fit, and the data seem to form a clear pattern (e.g., an S shape) around the line, then the variable may have to be transformed in some way .
See also, Normal Probability Plots (Computation Note)
Normality tests. A common application for distribution fitting procedures is when you want to verify the assumption of normality before using some parametric test (see Basic Statistics and Nonparametric Statistics). A variety of statistics for testing normality are available including the Kolmogorov-Smirnov test for normality, the Shapiro-Wilks' W test, and the Lilliefors test. Additionally, you may review probability plots and normal probability plots to assess whether the data are accurately modeled by a normal distribution.
Normalization.
Adjusting a series (vector) of values (typically representing a set of measurements, e.g., a variable storing heights of people, represented in inches) according to some transformation function in order to make them comparable with some specific point of reference (for example, a unit of length or a sum). For example, dividing these values by 2.54 will produce metric measurements of the height. Normalization of data is:
(a) required when the incompatibility of the measurement units across variables may affect the results (e.g., in calculations based on cross products) without carrying any interpretable information, and
(b) recommended whenever the final reports could benefit from expressing the results in specific meaningful/compatible units (e.g., reaction time data will be easier to interpret when converted into milliseconds from the CPU cycles of different computers that were used to measure RT's - as originally registered in a medical experiment).
Note that this term is unrelated to the term normal distribution; see also standardization.
