General Introduction
In the following topics, we will review techniques that are useful for analyzing time series data, that is, sequences of measurements that follow non-random orders. Unlike the analyses of random samples of observations that are discussed in the context of most other statistics, the analysis of time series is based on the assumption that successive values in the data file represent consecutive measurements taken at equally spaced time intervals.
Detailed discussions of the methods described in this section can be found in Anderson (1976), Box and Jenkins (1976), Kendall (1984), Kendall and Ord (1990), Montgomery, Johnson, and Gardiner (1990), Pankratz (1983), Shumway (1988), Vandaele (1983), Walker (1991), and Wei (1989).
Two Main Goals
There are two main goals of time series analysis: (a) identifying the nature of the phenomenon represented by the sequence of observations, and (b) forecasting (predicting future values of the time series variable). Both of these goals require that the pattern of observed time series data is identified and more or less formally described. Once the pattern is established, we can interpret and integrate it with other data (i.e., use it in our theory of the investigated phenomenon, e.g., sesonal commodity prices). Regardless of the depth of our understanding and the validity of our interpretation (theory) of the phenomenon, we can extrapolate the identified pattern to predict future events.
| To index |
Systematic Pattern and Random Noise
As in most other analyses, in time series analysis it is assumed that the data consist of a systematic pattern (usually a set of identifiable components) and random noise (error) which usually makes the pattern difficult to identify. Most time series analysis techniques involve some form of filtering out noise in order to make the pattern more salient.
Two General Aspects of Time Series Patterns
Most time series patterns can be described in terms of two basic classes of components: trend and seasonality. The former represents a general systematic linear or (most often) nonlinear component that changes over time and does not repeat or at least does not repeat within the time range captured by our data (e.g., a plateau followed by a period of exponential growth). The latter may have a formally similar nature (e.g., a plateau followed by a period of exponential growth), however, it repeats itself in systematic intervals over time. Those two general classes of time series components may coexist in real-life data. For example, sales of a company can rapidly grow over years but they still follow consistent seasonal patterns (e.g., as much as 25% of yearly sales each year are made in December, whereas only 4% in August).
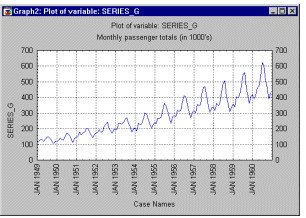
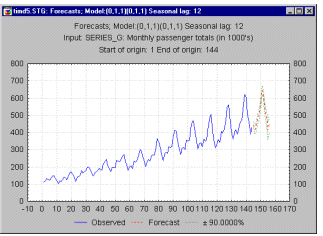
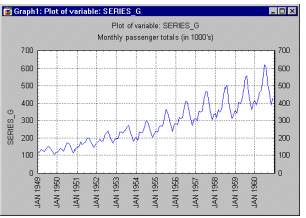
This general pattern is well illustrated in a "classic" Series G data set (Box and Jenkins, 1976, p. 531) representing monthly international airline passenger totals (measured in thousands) in twelve consecutive years from 1949 to 1960 (see example data file G.sta and graph above). If you plot the successive observations (months) of airline passenger totals, a clear, almost linear trend emerges, indicating that the airline industry enjoyed a steady growth over the years (approximately 4 times more passengers traveled in 1960 than in 1949). At the same time, the monthly figures will follow an almost identical pattern each year (e.g., more people travel during holidays then during any other time of the year). This example data file also illustrates a very common general type of pattern in time series data, where the amplitude of the seasonal changes increases with the overall trend (i.e., the variance is correlated with the mean over the segments of the series). This pattern which is called multiplicative seasonality indicates that the relative amplitude of seasonal changes is constant over time, thus it is related to the trend.
Trend Analysis
There are no proven "automatic" techniques to identify trend components in the time series data; however, as long as the trend is monotonous (consistently increasing or decreasing) that part of data analysis is typically not very difficult. If the time series data contain considerable error, then the first step in the process of trend identification is smoothing.
Smoothing. Smoothing always involves some form of local averaging of data such that the nonsystematic components of individual observations cancel each other out. The most common technique is moving average smoothing which replaces each element of the series by either the simple or weighted average of n surrounding elements, where n is the width of the smoothing "window" (see Box & Jenkins, 1976; Velleman & Hoaglin, 1981). Medians can be used instead of means. The main advantage of median as compared to moving average smoothing is that its results are less biased by outliers (within the smoothing window). Thus, if there are outliers in the data (e.g., due to measurement errors), median smoothing typically produces smoother or at least more "reliable" curves than moving average based on the same window width. The main disadvantage of median smoothing is that in the absence of clear outliers it may produce more "jagged" curves than moving average and it does not allow for weighting.
In the relatively less common cases (in time series data), when the measurement error is very large, the distance weighted least squares smoothing or negative exponentially weighted smoothing techniques can be used. All those methods will filter out the noise and convert the data into a smooth curve that is relatively unbiased by outliers (see the respective sections on each of those methods for more details). Series with relatively few and systematically distributed points can be smoothed with bicubic splines.
Fitting a function. Many monotonous time series data can be adequately approximated by a linear function; if there is a clear monotonous nonlinear component, the data first need to be transformed to remove the nonlinearity. Usually a logarithmic, exponential, or (less often) polynomial function can be used.
Analysis of Seasonality
Seasonal dependency (seasonality) is another general component of the time series pattern. The concept was illustrated in the example of the airline passengers data above. It is formally defined as correlational dependency of order k between each i'th element of the series and the (i-k)'th element (Kendall, 1976) and measured by autocorrelation (i.e., a correlation between the two terms); k is usually called the lag. If the measurement error is not too large, seasonality can be visually identified in the series as a pattern that repeats every k elements.
Autocorrelation correlogram. Seasonal patterns of time series can be examined via correlograms. The correlogram (autocorrelogram) displays graphically and numerically the autocorrelation function (ACF), that is, serial correlation coefficients (and their standard errors) for consecutive lags in a specified range of lags (e.g., 1 through 30). Ranges of two standard errors for each lag are usually marked in correlograms but typically the size of auto correlation is of more interest than its reliability (see Elementary Concepts) because we are usually interested only in very strong (and thus highly significant) autocorrelations.
Examining correlograms. While examining correlograms one should keep in mind that autocorrelations for consecutive lags are formally dependent. Consider the following example. If the first element is closely related to the second, and the second to the third, then the first element must also be somewhat related to the third one, etc. This implies that the pattern of serial dependencies can change considerably after removing the first order auto correlation (i.e., after differencing the series with a lag of 1).

Partial autocorrelations. Another useful method to examine serial dependencies is to examine the partial autocorrelation function (PACF) - an extension of autocorrelation, where the dependence on the intermediate elements (those within the lag) is removed. In other words the partial autocorrelation is similar to autocorrelation, except that when calculating it, the (auto) correlations with all the elements within the lag are partialled out (Box & Jenkins, 1976; see also McDowall, McCleary, Meidinger, & Hay, 1980). If a lag of 1 is specified (i.e., there are no intermediate elements within the lag), then the partial autocorrelation is equivalent to auto correlation. In a sense, the partial autocorrelation provides a "cleaner" picture of serial dependencies for individual lags (not confounded by other serial dependencies).
Removing serial dependency. Serial dependency for a particular lag of k can be removed by differencing the series, that is converting each i'th element of the series into its difference from the (i-k)''th element. There are two major reasons for such transformations.
First, one can identify the hidden nature of seasonal dependencies in the series. Remember that, as mentioned in the previous paragraph, autocorrelations for consecutive lags are interdependent. Therefore, removing some of the autocorrelations will change other auto correlations, that is, it may eliminate them or it may make some other seasonalities more apparent.
The other reason for removing seasonal dependencies is to make the series stationary which is necessary for ARIMA and other techniques.
| To index |
For more information on Time Series methods, see also:
General Introduction
The modeling and forecasting procedures discussed in the Identifying Patterns in Time Series Data, involved knowledge about the mathematical model of the process. However, in real-life research and practice, patterns of the data are unclear, individual observations involve considerable error, and we still need not only to uncover the hidden patterns in the data but also generate forecasts. The ARIMA methodology developed by Box and Jenkins (1976) allows us to do just that; it has gained enormous popularity in many areas and research practice confirms its power and flexibility (Hoff, 1983; Pankratz, 1983; Vandaele, 1983). However, because of its power and flexibility, ARIMA is a complex technique; it is not easy to use, it requires a great deal of experience, and although it often produces satisfactory results, those results depend on the researcher's level of expertise (Bails & Peppers, 1982). The following sections will introduce the basic ideas of this methodology. For those interested in a brief, applications-oriented (non- mathematical), introduction to ARIMA methods, we recommend McDowall, McCleary, Meidinger, and Hay (1980).
Two Common Processes
Autoregressive process. Most time series consist of elements that are serially dependent in the sense that one can estimate a coefficient or a set of coefficients that describe consecutive elements of the series from specific, time-lagged (previous) elements. This can be summarized in the equation:
xt = 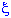 +
+  1*x(t-1) + 2*x(t-2) + 3*x(t-3) + ... +
1*x(t-1) + 2*x(t-2) + 3*x(t-3) + ... + 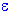
Where:
is a constant (intercept), and
1, 2, 3 are the autoregressive model parameters.
Put in words, each observation is made up of a random error component (random shock, ) and a linear combination of prior observations.
Stationarity requirement. Note that an autoregressive process will only be stable if the parameters are within a certain range; for example, if there is only one autoregressive parameter then is must fall within the interval of -1 < 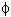 < 1. Otherwise, past effects would accumulate and the values of successive xt' s would move towards infinity, that is, the series would not be stationary. If there is more than one autoregressive parameter, similar (general) restrictions on the parameter values can be defined (e.g., see Box & Jenkins, 1976; Montgomery, 1990).
< 1. Otherwise, past effects would accumulate and the values of successive xt' s would move towards infinity, that is, the series would not be stationary. If there is more than one autoregressive parameter, similar (general) restrictions on the parameter values can be defined (e.g., see Box & Jenkins, 1976; Montgomery, 1990).
Moving average process. Independent from the autoregressive process, each element in the series can also be affected by the past error (or random shock) that cannot be accounted for by the autoregressive component, that is:
xt = µ + t
-  1*(t-1) - 2*(t-2) - 3*(t-3) - ...
1*(t-1) - 2*(t-2) - 3*(t-3) - ...
Where:
µ is a constant, and
1, 2, 3 are the moving average model parameters.
Put in words, each observation is made up of a random error component (random shock, ) and a linear combination of prior random shocks.
Invertibility requirement. Without going into too much detail, there is a "duality" between the moving average process and the autoregressive process (e.g., see Box & Jenkins, 1976; Montgomery, Johnson, & Gardiner, 1990), that is, the moving average equation above can be rewritten (inverted) into an autoregressive form (of infinite order). However, analogous to the stationarity condition described above, this can only be done if the moving average parameters follow certain conditions, that is, if the model is invertible. Otherwise, the series will not be stationary.
ARIMA Methodology
Autoregressive moving average model. The general model introduced by Box and Jenkins (1976) includes autoregressive as well as moving average parameters, and explicitly includes differencing in the formulation of the model. Specifically, the three types of parameters in the model are: the autoregressive parameters (p), the number of differencing passes (d), and moving average parameters (q). In the notation introduced by Box and Jenkins, models are summarized as ARIMA (p, d, q); so, for example, a model described as (0, 1, 2) means that it contains 0 (zero) autoregressive (p) parameters and 2 moving average (q) parameters which were computed for the series after it was differenced once.
Identification. As mentioned earlier, the input series for ARIMA needs to be stationary, that is, it should have a constant mean, variance, and autocorrelation through time. Therefore, usually the series first needs to be differenced until it is stationary (this also often requires log transforming the data to stabilize the variance). The number of times the series needs to be differenced to achieve stationarity is reflected in the d parameter (see the previous paragraph). In order to determine the necessary level of differencing, one should examine the plot of the data and autocorrelogram. Significant changes in level (strong upward or downward changes) usually require first order non seasonal (lag=1) differencing; strong changes of slope usually require second order non seasonal differencing. Seasonal patterns require respective seasonal differencing (see below). If the estimated autocorrelation coefficients decline slowly at longer lags, first order differencing is usually needed. However, one should keep in mind that some time series may require little or no differencing, and that over differenced series produce less stable coefficient estimates.
At this stage (which is usually called Identification phase, see below) we also need to decide how many autoregressive (p) and moving average (q) parameters are necessary to yield an effective but still parsimonious model of the process (parsimonious means that it has the fewest parameters and greatest number of degrees of freedom among all models that fit the data). In practice, the numbers of the p or q parameters very rarely need to be greater than 2 (see below for more specific recommendations).
Estimation and Forecasting. At the next step (Estimation), the parameters are estimated (using function minimization procedures, see below; for more information on minimization procedures see also Nonlinear Estimation), so that the sum of squared residuals is minimized. The estimates of the parameters are used in the last stage (Forecasting) to calculate new values of the series (beyond those included in the input data set) and confidence intervals for those predicted values. The estimation process is performed on transformed (differenced) data; before the forecasts are generated, the series needs to be integrated (integration is the inverse of differencing) so that the forecasts are expressed in values compatible with the input data. This automatic integration feature is represented by the letter I in the name of the methodology (ARIMA = Auto-Regressive Integrated Moving Average).
The constant in ARIMA models. In addition to the standard autoregressive and moving average parameters, ARIMA models may also include a constant, as described above. The interpretation of a (statistically significant) constant depends on the model that is fit. Specifically, (1) if there are no autoregressive parameters in the model, then the expected value of the constant is  , the mean of the series; (2) if there are autoregressive parameters in the series, then the constant represents the intercept. If the series is differenced, then the constant represents the mean or intercept of the differenced series; For example, if the series is differenced once, and there are no autoregressive parameters in the model, then the constant represents the mean of the differenced series, and therefore the linear trend slope of the un-differenced series.
, the mean of the series; (2) if there are autoregressive parameters in the series, then the constant represents the intercept. If the series is differenced, then the constant represents the mean or intercept of the differenced series; For example, if the series is differenced once, and there are no autoregressive parameters in the model, then the constant represents the mean of the differenced series, and therefore the linear trend slope of the un-differenced series.
Identification
Number of parameters to be estimated. Before the estimation can begin, we need to decide on (identify) the specific number and type of ARIMA parameters to be estimated. The major tools used in the identification phase are plots of the series, correlograms of auto correlation (ACF), and partial autocorrelation (PACF). The decision is not straightforward and in less typical cases requires not only experience but also a good deal of experimentation with alternative models (as well as the technical parameters of ARIMA). However, a majority of empirical time series patterns can be sufficiently approximated using one of the 5 basic models that can be identified based on the shape of the autocorrelogram (ACF) and partial auto correlogram (PACF). The following brief summary is based on practical recommendations of Pankratz (1983); for additional practical advice, see also Hoff (1983), McCleary and Hay (1980), McDowall, McCleary, Meidinger, and Hay (1980), and Vandaele (1983). Also, note that since the number of parameters (to be estimated) of each kind is almost never greater than 2, it is often practical to try alternative models on the same data.
The general recommendations concerning the selection of parameters to be estimated (based on ACF and PACF) also apply to seasonal models. The main difference is that in seasonal series, ACF and PACF will show sizable coefficients at multiples of the seasonal lag (in addition to their overall patterns reflecting the non seasonal components of the series).
Parameter Estimation
There are several different methods for estimating the parameters. All of them should produce very similar estimates, but may be more or less efficient for any given model. In general, during the parameter estimation phase a function minimization algorithm is used (the so-called quasi-Newton method; refer to the description of the Nonlinear Estimationmethod) to maximize the likelihood (probability) of the observed series, given the parameter values. In practice, this requires the calculation of the (conditional) sums of squares (SS) of the residuals, given the respective parameters. Different methods have been proposed to compute the SS for the residuals: (1) the approximate maximum likelihood method according to McLeod and Sales (1983), (2) the approximate maximum likelihood method with backcasting, and (3) the exact maximum likelihood method according to Melard (1984).
Comparison of methods. In general, all methods should yield very similar parameter estimates. Also, all methods are about equally efficient in most real-world time series applications. However, method 1 above, (approximate maximum likelihood, no backcasts) is the fastest, and should be used in particular for very long time series (e.g., with more than 30,000 observations). Melard's exact maximum likelihood method (number 3 above) may also become inefficient when used to estimate parameters for seasonal models with long seasonal lags (e.g., with yearly lags of 365 days). On the other hand, you should always use the approximate maximum likelihood method first in order to establish initial parameter estimates that are very close to the actual final values; thus, usually only a few iterations with the exact maximum likelihood method (3, above) are necessary to finalize the parameter estimates.
Parameter standard errors. For all parameter estimates, you will compute so-called asymptotic standard errors. These are computed from the matrix of second-order partial derivatives that is approximated via finite differencing (see also the respective discussion in Nonlinear Estimation).
Penalty value. As mentioned above, the estimation procedure requires that the (conditional) sums of squares of the ARIMA residuals be minimized. If the model is inappropriate, it may happen during the iterative estimation process that the parameter estimates become very large, and, in fact, invalid. In that case, the it will assign a very large value (a so-called penalty value) to the SS. This usually "entices" the iteration process to move the parameters away from invalid ranges. However, in some cases even this strategy fails, and you may see on the screen (during the Estimation procedure) very large values for the SS in consecutive iterations. In that case, carefully evaluate the appropriateness of your model. If your model contains many parameters, and perhaps an intervention component (see below), you may try again with different parameter start values.
Evaluation of the Model
Parameter estimates. You will report approximate t values, computed from the parameter standard errors (see above). If not significant, the respective parameter can in most cases be dropped from the model without affecting substantially the overall fit of the model.
Other quality criteria. Another straightforward and common measure of the reliability of the model is the accuracy of its forecasts generated based on partial data so that the forecasts can be compared with known (original) observations.
However, a good model should not only provide sufficiently accurate forecasts, it should also be parsimonious and produce statistically independent residuals that contain only noise and no systematic components (e.g., the correlogram of residuals should not reveal any serial dependencies). A good test of the model is (a) to plot the residuals and inspect them for any systematic trends, and (b) to examine the autocorrelogram of residuals (there should be no serial dependency between residuals).
Analysis of residuals. The major concern here is that the residuals are systematically distributed across the series (e.g., they could be negative in the first part of the series and approach zero in the second part) or that they contain some serial dependency which may suggest that the ARIMA model is inadequate. The analysis of ARIMA residuals constitutes an important test of the model. The estimation procedure assumes that the residual are not (auto-) correlated and that they are normally distributed.
Limitations. The ARIMA method is appropriate only for a time series that is stationary (i.e., its mean, variance, and autocorrelation should be approximately constant through time) and it is recommended that there are at least 50 observations in the input data. It is also assumed that the values of the estimated parameters are constant throughout the series.
Interrupted Time Series ARIMA
A common research questions in time series analysis is whether an outside event affected subsequent observations. For example, did the implementation of a new economic policy improve economic performance; did the a new anti-crime law affect subsequent crime rates; and so on. In general, we would like to evaluate the impact of one or more discrete events on the values in the time series. This type of interrupted time series analysis is described in detail in McDowall, McCleary, Meidinger, & Hay (1980). McDowall, et. al., distinguish between three major types of impacts that are possible: (1) permanent abrupt, (2) permanent gradual, and (3) abrupt temporary. See also:
| To index |
General Introduction
Exponential smoothing has become very popular as a forecasting method for a wide variety of time series data. Historically, the method was independently developed by Brown and Holt. Brown worked for the US Navy during World War II, where his assignment was to design a tracking system for fire-control information to compute the location of submarines. Later, he applied this technique to the forecasting of demand for spare parts (an inventory control problem). He described those ideas in his 1959 book on inventory control. Holt's research was sponsored by the Office of Naval Research; independently, he developed exponential smoothing models for constant processes, processes with linear trends, and for seasonal data.
Gardner (1985) proposed a "unified" classification of exponential smoothing methods. Excellent introductions can also be found in Makridakis, Wheelwright, and McGee (1983), Makridakis and Wheelwright (1989), Montgomery, Johnson, & Gardiner (1990).
Simple Exponential Smoothing
A simple and pragmatic model for a time series would be to consider each observation as consisting of a constant (b) and an error component  (epsilon), that is: Xt = b + t. The constant b is relatively stable in each segment of the series, but may change slowly over time. If appropriate, then one way to isolate the true value of b, and thus the systematic or predictable part of the series, is to compute a kind of moving average, where the current and immediately preceding ("younger") observations are assigned greater weight than the respective older observations. Simple exponential smoothing accomplishes exactly such weighting, where exponentially smaller weights are assigned to older observations. The specific formula for simple exponential smoothing is:
(epsilon), that is: Xt = b + t. The constant b is relatively stable in each segment of the series, but may change slowly over time. If appropriate, then one way to isolate the true value of b, and thus the systematic or predictable part of the series, is to compute a kind of moving average, where the current and immediately preceding ("younger") observations are assigned greater weight than the respective older observations. Simple exponential smoothing accomplishes exactly such weighting, where exponentially smaller weights are assigned to older observations. The specific formula for simple exponential smoothing is:
St =  *Xt + (1-)*St-1
*Xt + (1-)*St-1
When applied recursively to each successive observation in the series, each new smoothed value (forecast) is computed as the weighted average of the current observation and the previous smoothed observation; the previous smoothed observation was computed in turn from the previous observed value and the smoothed value before the previous observation, and so on. Thus, in effect, each smoothed value is the weighted average of the previous observations, where the weights decrease exponentially depending on the value of parameter (alpha). If is equal to 1 (one) then the previous observations are ignored entirely; if is equal to 0 (zero), then the current observation is ignored entirely, and the smoothed value consists entirely of the previous smoothed value (which in turn is computed from the smoothed observation before it, and so on; thus all smoothed values will be equal to the initial smoothed value S0). Values of in-between will produce intermediate results.
Even though significant work has been done to study the theoretical properties of (simple and complex) exponential smoothing (e.g., see Gardner, 1985; Muth, 1960; see also McKenzie, 1984, 1985), the method has gained popularity mostly because of its usefulness as a forecasting tool. For example, empirical research by Makridakis et al. (1982, Makridakis, 1983), has shown simple exponential smoothing to be the best choice for one-period-ahead forecasting, from among 24 other time series methods and using a variety of accuracy measures (see also Gross and Craig, 1974, for additional empirical evidence). Thus, regardless of the theoretical model for the process underlying the observed time series, simple exponential smoothing will often produce quite accurate forecasts.
Choosing the Best Value for Parameter 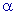 (alpha)
(alpha)
Gardner (1985) discusses various theoretical and empirical arguments for selecting an appropriate smoothing parameter. Obviously, looking at the formula presented above, 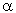 should fall into the interval between 0 (zero) and 1 (although, see Brenner et al., 1968, for an ARIMA perspective, implying 0<<2). Gardner (1985) reports that among practitioners, an smaller than .30 is usually recommended. However, in the study by Makridakis et al. (1982), values above .30 frequently yielded the best forecasts. After reviewing the literature on this topic, Gardner (1985) concludes that it is best to estimate an optimum from the data (see below), rather than to "guess" and set an artificially low value.
should fall into the interval between 0 (zero) and 1 (although, see Brenner et al., 1968, for an ARIMA perspective, implying 0<<2). Gardner (1985) reports that among practitioners, an smaller than .30 is usually recommended. However, in the study by Makridakis et al. (1982), values above .30 frequently yielded the best forecasts. After reviewing the literature on this topic, Gardner (1985) concludes that it is best to estimate an optimum from the data (see below), rather than to "guess" and set an artificially low value.
Estimating the best value from the data. In practice, the smoothing parameter is often chosen by a grid search of the parameter space; that is, different solutions for are tried starting, for example, with = 0.1 to = 0.9, with increments of 0.1. Then is chosen so as to produce the smallest sums of squares (or mean squares) for the residuals (i.e., observed values minus one-step-ahead forecasts; this mean squared error is also referred to as ex post mean squared error, ex post MSE for short).
Indices of Lack of Fit (Error)
The most straightforward way of evaluating the accuracy of the forecasts based on a particular value is to simply plot the observed values and the one-step-ahead forecasts. This plot can also include the residuals (scaled against the right Y-axis), so that regions of better or worst fit can also easily be identified.
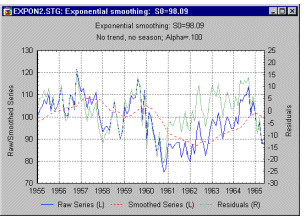
This visual check of the accuracy of forecasts is often the most powerful method for determining whether or not the current exponential smoothing model fits the data. In addition, besides the ex post MSE criterion (see previous paragraph), there are other statistical measures of error that can be used to determine the optimum parameter (see Makridakis, Wheelwright, and McGee, 1983):
Mean error: The mean error (ME) value is simply computed as the average error value (average of observed minus one-step-ahead forecast). Obviously, a drawback of this measure is that positive and negative error values can cancel each other out, so this measure is not a very good indicator of overall fit.
Mean absolute error: The mean absolute error (MAE) value is computed as the average absolute error value. If this value is 0 (zero), the fit (forecast) is perfect. As compared to the mean squared error value, this measure of fit will "de-emphasize" outliers, that is, unique or rare large error values will affect the MAE less than the MSE value.
Sum of squared error (SSE), Mean squared error. These values are computed as the sum (or average) of the squared error values. This is the most commonly used lack-of-fit indicator in statistical fitting procedures.
Percentage error (PE). All the above measures rely on the actual error value. It may seem reasonable to rather express the lack of fit in terms of the relative deviation of the one-step-ahead forecasts from the observed values, that is, relative to the magnitude of the observed values. For example, when trying to predict monthly sales that may fluctuate widely (e.g., seasonally) from month to month, we may be satisfied if our prediction "hits the target" with about �10% accuracy. In other words, the absolute errors may be not so much of interest as are the relative errors in the forecasts. To assess the relative error, various indices have been proposed (see Makridakis, Wheelwright, and McGee, 1983). The first one, the percentage error value, is computed as:
PEt = 100*(Xt - Ft )/Xt
where Xt is the observed value at time t, and Ft is the forecasts (smoothed values).
Mean percentage error (MPE). This value is computed as the average of the PE values.
Mean absolute percentage error (MAPE). As is the case with the mean error value (ME, see above), a mean percentage error near 0 (zero) can be produced by large positive and negative percentage errors that cancel each other out. Thus, a better measure of relative overall fit is the mean absolute percentage error. Also, this measure is usually more meaningful than the mean squared error. For example, knowing that the average forecast is "off" by �5% is a useful result in and of itself, whereas a mean squared error of 30.8 is not immediately interpretable.
Automatic search for best parameter. A quasi-Newton function minimization procedure (the same as in ARIMA is used to minimize either the mean squared error, mean absolute error, or mean absolute percentage error. In most cases, this procedure is more efficient than the grid search (particularly when more than one parameter must be determined), and the optimum parameter can quickly be identified.
The first smoothed value S0. A final issue that we have neglected up to this point is the problem of the initial value, or how to start the smoothing process. If you look back at the formula above, it is evident that one needs an S0 value in order to compute the smoothed value (forecast) for the first observation in the series. Depending on the choice of the parameter (i.e., when is close to zero), the initial value for the smoothing process can affect the quality of the forecasts for many observations. As with most other aspects of exponential smoothing it is recommended to choose the initial value that produces the best forecasts. On the other hand, in practice, when there are many leading observations prior to a crucial actual forecast, the initial value will not affect that forecast by much, since its effect will have long "faded" from the smoothed series (due to the exponentially decreasing weights, the older an observation the less it will influence the forecast).
Seasonal and Non-seasonal Models With or Without Trend
The discussion above in the context of simple exponential smoothing introduced the basic procedure for identifying a smoothing parameter, and for evaluating the goodness-of-fit of a model. In addition to simple exponential smoothing, more complex models have been developed to accommodate time series with seasonal and trend components. The general idea here is that forecasts are not only computed from consecutive previous observations (as in simple exponential smoothing), but an independent (smoothed) trend and seasonal component can be added. Gardner (1985) discusses the different models in terms of seasonality (none, additive, or multiplicative) and trend (none, linear, exponential, or damped).
Additive and multiplicative seasonality. Many time series data follow recurring seasonal patterns. For example, annual sales of toys will probably peak in the months of November and December, and perhaps during the summer (with a much smaller peak) when children are on their summer break. This pattern will likely repeat every year, however, the relative amount of increase in sales during December may slowly change from year to year. Thus, it may be useful to smooth the seasonal component independently with an extra parameter, usually denoted as 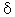 (delta). Seasonal components can be additive in nature or multiplicative. For example, during the month of December the sales for a particular toy may increase by 1 million dollars every year. Thus, we could add to our forecasts for every December the amount of 1 million dollars (over the respective annual average) to account for this seasonal fluctuation. In this case, the seasonality is additive. Alternatively, during the month of December the sales for a particular toy may increase by 40%, that is, increase by a factor of 1.4. Thus, when the sales for the toy are generally weak, than the absolute (dollar) increase in sales during December will be relatively weak (but the percentage will be constant); if the sales of the toy are strong, than the absolute (dollar) increase in sales will be proportionately greater. Again, in this case the sales increase by a certain factor, and the seasonal component is thus multiplicative in nature (i.e., the multiplicative seasonal component in this case would be 1.4). In plots of the series, the distinguishing characteristic between these two types of seasonal components is that in the additive case, the series shows steady seasonal fluctuations, regardless of the overall level of the series; in the multiplicative case, the size of the seasonal fluctuations vary, depending on the overall level of the series.
(delta). Seasonal components can be additive in nature or multiplicative. For example, during the month of December the sales for a particular toy may increase by 1 million dollars every year. Thus, we could add to our forecasts for every December the amount of 1 million dollars (over the respective annual average) to account for this seasonal fluctuation. In this case, the seasonality is additive. Alternatively, during the month of December the sales for a particular toy may increase by 40%, that is, increase by a factor of 1.4. Thus, when the sales for the toy are generally weak, than the absolute (dollar) increase in sales during December will be relatively weak (but the percentage will be constant); if the sales of the toy are strong, than the absolute (dollar) increase in sales will be proportionately greater. Again, in this case the sales increase by a certain factor, and the seasonal component is thus multiplicative in nature (i.e., the multiplicative seasonal component in this case would be 1.4). In plots of the series, the distinguishing characteristic between these two types of seasonal components is that in the additive case, the series shows steady seasonal fluctuations, regardless of the overall level of the series; in the multiplicative case, the size of the seasonal fluctuations vary, depending on the overall level of the series.
The seasonal smoothing parameter. In general the one-step-ahead forecasts are computed as (for no trend models, for linear and exponential trend models a trend component is added to the model; see below):
Additive model:
Forecastt = St + It-p
Multiplicative model:
Forecastt = St*It-p
In this formula, St stands for the (simple) exponentially smoothed value of the series at time t, and It-p stands for the smoothed seasonal factor at time t minus p (the length of the season). Thus, compared to simple exponential smoothing, the forecast is "enhanced" by adding or multiplying the simple smoothed value by the predicted seasonal component. This seasonal component is derived analogous to the St value from simple exponential smoothing as:
Additive model:
It = It-p + 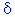 *(1-)*et
*(1-)*et
Multiplicative model:
It = It-p + *(1-)*et/St
Put in words, the predicted seasonal component at time t is computed as the respective seasonal component in the last seasonal cycle plus a portion of the error (et; the observed minus the forecast value at time t). Considering the formulas above, it is clear that parameter can assume values between 0 and 1. If it is zero, then the seasonal component for a particular point in time is predicted to be identical to the predicted seasonal component for the respective time during the previous seasonal cycle, which in turn is predicted to be identical to that from the previous cycle, and so on. Thus, if is zero, a constant unchanging seasonal component is used to generate the one-step-ahead forecasts. If the parameter is equal to 1, then the seasonal component is modified "maximally" at every step by the respective forecast error (times (1-), which we will ignore for the purpose of this brief introduction). In most cases, when seasonality is present in the time series, the optimum parameter will fall somewhere between 0 (zero) and 1(one).
Linear, exponential, and damped trend. To remain with the toy example above, the sales for a toy can show a linear upward trend (e.g., each year, sales increase by 1 million dollars), exponential growth (e.g., each year, sales increase by a factor of 1.3), or a damped trend (during the first year sales increase by 1 million dollars; during the second year the increase is only 80% over the previous year, i.e., $800,000; during the next year it is again 80% less than the previous year, i.e., $800,000 * .8 = $640,000; etc.). Each type of trend leaves a clear "signature" that can usually be identified in the series; shown below in the brief discussion of the different models are icons that illustrate the general patterns. In general, the trend factor may change slowly over time, and, again, it may make sense to smooth the trend component with a separate parameter (denoted 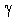 [gamma] for linear and exponential trend models, and
[gamma] for linear and exponential trend models, and 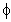 [phi] for damped trend models).
[phi] for damped trend models).
The trend smoothing parameters (linear and exponential trend) and (damped trend). Analogous to the seasonal component, when a trend component is included in the exponential smoothing process, an independent trend component is computed for each time, and modified as a function of the forecast error and the respective parameter. If the parameter is 0 (zero), than the trend component is constant across all values of the time series (and for all forecasts). If the parameter is 1, then the trend component is modified "maximally" from observation to observation by the respective forecast error. Parameter values that fall in-between represent mixtures of those two extremes. Parameter is a trend modification parameter, and affects how strongly changes in the trend will affect estimates of the trend for subsequent forecasts, that is, how quickly the trend will be "damped" or increased.
| To index |
Suppose you recorded the monthly passenger load on international flights for a period of 12 years ( see Box & Jenkins, 1976). If you plot those data, it is apparent that (1) there appears to be a linear upwards trend in the passenger loads over the years, and (2) there is a recurring pattern or seasonality within each year (i.e., most travel occurs during the summer months, and a minor peak occurs during the December holidays). The purpose of the seasonal decomposition method is to isolate those components, that is, to de-compose the series into the trend effect, seasonal effects, and remaining variability. The "classic" technique designed to accomplish this decomposition is known as the Census I method. This technique is described and discussed in detail in Makridakis, Wheelwright, and McGee (1983), and Makridakis and Wheelwright (1989).
General model. The general idea of seasonal decomposition is straightforward. In general, a time series like the one described above can be thought of as consisting of four different components: (1) A seasonal component (denoted as St, where t stands for the particular point in time) (2) a trend component (Tt), (3) a cyclical component (Ct), and (4) a random, error, or irregular component (It). The difference between a cyclical and a seasonal component is that the latter occurs at regular (seasonal) intervals, while cyclical factors have usually a longer duration that varies from cycle to cycle. In the Census I method, the trend and cyclical components are customarily combined into a trend-cycle component (TCt). The specific functional relationship between these components can assume different forms. However, two straightforward possibilities are that they combine in an additive or a multiplicative fashion:
Additive model:
Xt = TCt + St + It
Multiplicative model:
Xt = Tt*Ct*St*It
Here Xt stands for the observed value of the time series at time t. Given some a priori knowledge about the cyclical factors affecting the series (e.g., business cycles), the estimates for the different components can be used to compute forecasts for future observations. (However, the Exponential smoothing method, which can also incorporate seasonality and trend components, is the preferred technique for forecasting purposes.)
Additive and multiplicative seasonality. Let us consider the difference between an additive and multiplicative seasonal component in an example: The annual sales of toys will probably peak in the months of November and December, and perhaps during the summer (with a much smaller peak) when children are on their summer break. This seasonal pattern will likely repeat every year. Seasonal components can be additive or multiplicative in nature. For example, during the month of December the sales for a particular toy may increase by 3 million dollars every year. Thus, we could add to our forecasts for every December the amount of 3 million to account for this seasonal fluctuation. In this case, the seasonality is additive. Alternatively, during the month of December the sales for a particular toy may increase by 40%, that is, increase by a factor of 1.4. Thus, when the sales for the toy are generally weak, then the absolute (dollar) increase in sales during December will be relatively weak (but the percentage will be constant); if the sales of the toy are strong, then the absolute (dollar) increase in sales will be proportionately greater. Again, in this case the sales increase by a certain factor, and the seasonal component is thus multiplicative in nature (i.e., the multiplicative seasonal component in this case would be 1.4). In plots of series, the distinguishing characteristic between these two types of seasonal components is that in the additive case, the series shows steady seasonal fluctuations, regardless of the overall level of the series; in the multiplicative case, the size of the seasonal fluctuations vary, depending on the overall level of the series.
Additive and multiplicative trend-cycle. We can extend the previous example to illustrate the additive and multiplicative trend-cycle components. In terms of our toy example, a "fashion" trend may produce a steady increase in sales (e.g., a trend towards more educational toys in general); as with the seasonal component, this trend may be additive (sales increase by 3 million dollars per year) or multiplicative (sales increase by 30%, or by a factor of 1.3, annually) in nature. In addition, cyclical components may impact sales; to reiterate, a cyclical component is different from a seasonal component in that it usually is of longer duration, and that it occurs at irregular intervals. For example, a particular toy may be particularly "hot" during a summer season (e.g., a particular doll which is tied to the release of a major children's movie, and is promoted with extensive advertising). Again such a cyclical component can effect sales in an additive manner or multiplicative manner.
Computations
The Seasonal Decomposition (Census I) standard formulas are shown in Makridakis, Wheelwright, and McGee (1983), and Makridakis and Wheelwright (1989).
Moving average. First a moving average is computed for the series, with the moving average window width equal to the length of one season. If the length of the season is even, then the user can choose to use either equal weights for the moving average or unequal weights can be used, where the first and last observation in the moving average window are averaged.
Ratios or differences. In the moving average series, all seasonal (within-season) variability will be eliminated; thus, the differences (in additive models) or ratios (in multiplicative models) of the observed and smoothed series will isolate the seasonal component (plus irregular component). Specifically, the moving average is subtracted from the observed series (for additive models) or the observed series is divided by the moving average values (for multiplicative models).
Seasonal components. The seasonal component is then computed as the average (for additive models) or medial average (for multiplicative models) for each point in the season.

(The medial average of a set of values is the mean after the smallest and largest values are excluded). The resulting values represent the (average) seasonal component of the series.
Seasonally adjusted series. The original series can be adjusted by subtracting from it (additive models) or dividing it by (multiplicative models) the seasonal component.
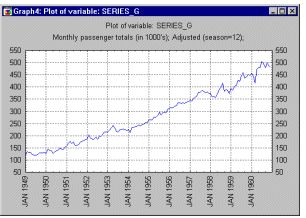
The resulting series is the seasonally adjusted series (i.e., the seasonal component will be removed).
Trend-cycle component. Remember that the cyclical component is different from the seasonal component in that it is usually longer than one season, and different cycles can be of different lengths. The combined trend and cyclical component can be approximated by applying to the seasonally adjusted series a 5 point (centered) weighed moving average smoothing transformation with the weights of 1, 2, 3, 2, 1.
Random or irregular component. Finally, the random or irregular (error) component can be isolated by subtracting from the seasonally adjusted series (additive models) or dividing the adjusted series by (multiplicative models) the trend-cycle component.
| To index |
The general ideas of seasonal decomposition and adjustment are discussed in the context of the Census I seasonal adjustment method (Seasonal Decomposition (Census I)). The Census method II (2) is an extension and refinement of the simple adjustment method. Over the years, different versions of the Census method II evolved at the Census Bureau; the method that has become most popular and is used most widely in government and business is the so-called X-11 variant of the Census method II (see Hiskin, Young, & Musgrave, 1967). Subsequently, the term X-11 has become synonymous with this refined version of the Census method II. In addition to the documentation that can be obtained from the Census Bureau, a detailed summary of this method is also provided in Makridakis, Wheelwright, and McGee (1983) and Makridakis and Wheelwright (1989).
For more information on this method, see the following topics:
Suppose you recorded the monthly passenger load on international flights for a period of 12 years ( see Box & Jenkins, 1976). If you plot those data, it is apparent that (1) there appears to be an upwards linear trend in the passenger loads over the years, and (2) there is a recurring pattern or seasonality within each year (i.e., most travel occurs during the summer months, and a minor peak occurs during the December holidays). The purpose of seasonal decomposition and adjustment is to isolate those components, that is, to de-compose the series into the trend effect, seasonal effects, and remaining variability. The "classic" technique designed to accomplish this decomposition was developed in the 1920's and is also known as the Census I method (see the Census I overview section). This technique is also described and discussed in detail in Makridakis, Wheelwright, and McGee (1983), and Makridakis and Wheelwright (1989).
General model. The general idea of seasonal decomposition is straightforward. In general, a time series like the one described above can be thought of as consisting of four different components: (1) A seasonal component (denoted as St, where t stands for the particular point in time) (2) a trend component (Tt), (3) a cyclical component (Ct), and (4) a random, error, or irregular component (It). The difference between a cyclical and a seasonal component is that the latter occurs at regular (seasonal) intervals, while cyclical factors usually have a longer duration that varies from cycle to cycle. The trend and cyclical components are customarily combined into a trend-cycle component (TCt). The specific functional relationship between these components can assume different forms. However, two straightforward possibilities are that they combine in an additive or a multiplicative fashion:
Additive Model:
Xt = TCt + St + It
Multiplicative Model:
Xt = Tt*Ct*St*It
Where:
Xt represents the observed value of the time series at time t.
Given some a priori knowledge about the cyclical factors affecting the series (e.g., business cycles), the estimates for the different components can be used to compute forecasts for future observations. (However, the Exponential smoothing method, which can also incorporate seasonality and trend components, is the preferred technique for forecasting purposes.)
Additive and multiplicative seasonality. Consider the difference between an additive and multiplicative seasonal component in an example: The annual sales of toys will probably peak in the months of November and December, and perhaps during the summer (with a much smaller peak) when children are on their summer break. This seasonal pattern will likely repeat every year. Seasonal components can be additive or multiplicative in nature. For example, during the month of December the sales for a particular toy may increase by 3 million dollars every year. Thus, you could add to your forecasts for every December the amount of 3 million to account for this seasonal fluctuation. In this case, the seasonality is additive. Alternatively, during the month of December the sales for a particular toy may increase by 40%, that is, increase by a factor of 1.4. Thus, when the sales for the toy are generally weak, then the absolute (dollar) increase in sales during December will be relatively weak (but the percentage will be constant); if the sales of the toy are strong, then the absolute (dollar) increase in sales will be proportionately greater. Again, in this case the sales increase by a certain factor, and the seasonal component is thus multiplicative in nature (i.e., the multiplicative seasonal component in this case would be 1.4). In plots of series, the distinguishing characteristic between these two types of seasonal components is that in the additive case, the series shows steady seasonal fluctuations, regardless of the overall level of the series; in the multiplicative case, the size of the seasonal fluctuations vary, depending on the overall level of the series.
Additive and multiplicative trend-cycle. The previous example can be extended to illustrate the additive and multiplicative trend-cycle components. In terms of the toy example, a "fashion" trend may produce a steady increase in sales (e.g., a trend towards more educational toys in general); as with the seasonal component, this trend may be additive (sales increase by 3 million dollars per year) or multiplicative (sales increase by 30%, or by a factor of 1.3, annually) in nature. In addition, cyclical components may impact sales. To reiterate, a cyclical component is different from a seasonal component in that it usually is of longer duration, and that it occurs at irregular intervals. For example, a particular toy may be particularly "hot" during a summer season (e.g., a particular doll which is tied to the release of a major children's movie, and is promoted with extensive advertising). Again such a cyclical component can effect sales in an additive manner or multiplicative manner.
The Census II Method
The basic method for seasonal decomposition and adjustment outlined in the Basic Ideas and Terms topic can be refined in several ways. In fact, unlike many other time-series modeling techniques (e.g., ARIMA) which are grounded in some theoretical model of an underlying process, the X-11 variant of the Census II method simply contains many ad hoc features and refinements, that over the years have proven to provide excellent estimates for many real-world applications (see Burman, 1979, Kendal & Ord, 1990, Makridakis & Wheelwright, 1989; Wallis, 1974). Some of the major refinements are listed below.
Trading-day adjustment. Different months have different numbers of days, and different numbers of trading-days (i.e., Mondays, Tuesdays, etc.). When analyzing, for example, monthly revenue figures for an amusement park, the fluctuation in the different numbers of Saturdays and Sundays (peak days) in the different months will surely contribute significantly to the variability in monthly revenues. The X-11 variant of the Census II method allows the user to test whether such trading-day variability exists in the series, and, if so, to adjust the series accordingly.
Extreme values. Most real-world time series contain outliers, that is, extreme fluctuations due to rare events. For example, a strike may affect production in a particular month of one year. Such extreme outliers may bias the estimates of the seasonal and trend components. The X-11 procedure includes provisions to deal with extreme values through the use of "statistical control principles," that is, values that are above or below a certain range (expressed in terms of multiples of sigma, the standard deviation) can be modified or dropped before final estimates for the seasonality are computed.
Multiple refinements. The refinement for outliers, extreme values, and different numbers of trading-days can be applied more than once, in order to obtain successively improved estimates of the components. The X-11 method applies a series of successive refinements of the estimates to arrive at the final trend-cycle, seasonal, and irregular components, and the seasonally adjusted series.
Tests and summary statistics. In addition to estimating the major components of the series, various summary statistics can be computed. For example, analysis of variance tables can be prepared to test the significance of seasonal variability and trading-day variability (see above) in the series; the X-11 procedure will also compute the percentage change from month to month in the random and trend-cycle components. As the duration or span in terms of months (or quarters for quarterly X-11) increases, the change in the trend-cycle component will likely also increase, while the change in the random component should remain about the same. The width of the average span at which the changes in the random component are about equal to the changes in the trend-cycle component is called the month (quarter) for cyclical dominance, or MCD (QCD) for short. For example, if the MCD is equal to 2 then one can infer that over a 2 month span the trend-cycle will dominate the fluctuations of the irregular (random) component. These and various other results are discussed in greater detail below.
Result Tables Computed by the X-11 Method
The computations performed by the X-11 procedure are best discussed in the context of the results tables that are reported. The adjustment process is divided into seven major steps, which are customarily labeled with consecutive letters A through G.
Specific Description of all Result Tables Computed by the X-11 Method
In each part A through G of the analysis (see Results Tables Computed by the X-11 Method), different result tables are computed. Customarily, these tables are numbered, and also identified by a letter to indicate the respective part of the analysis. For example, table B 11 shows the initial seasonally adjusted series; C 11 is the refined seasonally adjusted series, and D 11 is the final seasonally adjusted series. Shown below is a list of all available tables. Those tables identified by an asterisk (*) are not available (applicable) when analyzing quarterly series. (Also, for quarterly adjustment, some of the computations outlined below are slightly different; for example instead of a 12-term [monthly] moving average, a 4-term [quarterly] moving average is applied to compute the seasonal factors; the initial trend-cycle estimate is computed via a centered 4-term moving average, the final trend-cycle estimate in each part is computed by a 5-term Henderson average.)
Following the convention of the Bureau of the Census version of the X-11 method, three levels of printout detail are offered: Standard (17 to 27 tables), Long (27 to 39 tables), and Full (44 to 59 tables). In the description of each table below, the letters S, L, and F are used next to each title to indicate, which tables will be displayed and/or printed at the respective setting of the output option. (For the charts, two levels of detail are available: Standard and All.)
See the table name below, to obtain more information about that table.
| To index |
Distributed lags analysis is a specialized technique for examining the relationships between variables that involve some delay. For example, suppose that you are a manufacturer of computer software, and you want to determine the relationship between the number of inquiries that are received, and the number of orders that are placed by your customers. You could record those numbers monthly for a one year period, and then correlate the two variables. However, obviously inquiries will precede actual orders, and one can expect that the number of orders will follow the number of inquiries with some delay. Put another way, there will be a (time) lagged correlation between the number of inquiries and the number of orders that are received.
Time-lagged correlations are particularly common in econometrics. For example, the benefits of investments in new machinery usually only become evident after some time. Higher income will change people's choice of rental apartments, however, this relationship will be lagged because it will take some time for people to terminate their current leases, find new apartments, and move. In general, the relationship between capital appropriations and capital expenditures will be lagged, because it will require some time before investment decisions are actually acted upon.
In all of these cases, we have an independent or explanatory variable that affects the dependent variables with some lag. The distributed lags method allows you to investigate those lags.
Detailed discussions of distributed lags correlation can be found in most econometrics textbooks, for example, in Judge, Griffith, Hill, Luetkepohl, and Lee (1985), Maddala (1977), and Fomby, Hill, and Johnson (1984). In the following paragraphs we will present a brief description of these methods. We will assume that you are familiar with the concept of correlation (see Basic Statistics), and the basic ideas of multiple regression (see Multiple Regression).
General Model
Suppose we have a dependent variable y and an independent or explanatory variable x which are both measured repeatedly over time. In some textbooks, the dependent variable is also referred to as the endogenous variable, and the independent or explanatory variable the exogenous variable. The simplest way to describe the relationship between the two would be in a simple linear relationship:
Yt =
In this equation, the value of the dependent variable at time t is expressed as a linear function of x measured at times t, t-1, t-2, etc. Thus, the dependent variable is a linear function of x, and x is lagged by 1, 2, etc. time periods. The beta weights ( Almon Distributed Lag
A common problem that often arises when computing the weights for the multiple linear regression model shown above is that the values of adjacent (in time) values in the x variable are highly correlated. In extreme cases, their independent contributions to the prediction of y may become so redundant that the correlation matrix of measures can no longer be inverted, and thus, the beta weights cannot be computed. In less extreme cases, the computation of the beta weights and their standard errors can become very imprecise, due to round-off error. In the context of Multiple Regression this general computational problem is discussed as the multicollinearity or matrix ill-conditioning issue.
Almon (1965) proposed a procedure that will reduce the multicollinearity in this case. Specifically, suppose we express each weight in the linear regression equation in the following manner:
Almon could show that in many cases it is easier (i.e., it avoids the multicollinearity problem) to estimate the alpha values than the beta weights directly. Note that with this method, the precision of the beta weight estimates is dependent on the degree or order of the polynomial approximation.
Misspecifications. A general problem with this technique is that, of course, the lag length and correct polynomial degree are not known a priori. The effects of misspecifications of these parameters are potentially serious (in terms of biased estimation). This issue is discussed in greater detail in Frost (1975), Schmidt and Waud (1973), Schmidt and Sickles (1975), and Trivedi and Pagan (1979).
Spectrum analysis is concerned with the exploration of cyclical patterns of data. The purpose of the analysis is to decompose a complex time series with cyclical components into a few underlying sinusoidal (sine and cosine) functions of particular wavelengths. The term "spectrum" provides an appropriate metaphor for the nature of this analysis: Suppose you study a beam of white sun light, which at first looks like a random (white noise) accumulation of light of different wavelengths. However, when put through a prism, we can separate the different wave lengths or cyclical components that make up white sun light. In fact, via this technique we can now identify and distinguish between different sources of light. Thus, by identifying the important underlying cyclical components, we have learned something about the phenomenon of interest. In essence, performing spectrum analysis on a time series is like putting the series through a prism in order to identify the wave lengths and importance of underlying cyclical components. As a result of a successful analysis one might uncover just a few recurring cycles of different lengths in the time series of interest, which at first looked more or less like random noise.
A much cited example for spectrum analysis is the cyclical nature of sun spot activity (e.g., see Bloomfield, 1976, or Shumway, 1988). It turns out that sun spot activity varies over 11 year cycles. Other examples of celestial phenomena, weather patterns, fluctuations in commodity prices, economic activity, etc. are also often used in the literature to demonstrate this technique. To contrast this technique with ARIMA or Exponential Smoothing, the purpose of spectrum analysis is to identify the seasonal fluctuations of different lengths, while in the former types of analysis, the length of the seasonal component is usually known (or guessed) a priori and then included in some theoretical model of moving averages or autocorrelations.
The classic text on spectrum analysis is Bloomfield (1976); however, other detailed discussions can be found in Jenkins and Watts (1968), Brillinger (1975), Brigham (1974), Elliott and Rao (1982), Priestley (1981), Shumway (1988), or Wei (1989).
For more information, see Time Series Analysis - Index and the following topics:
 i*xt-i
i) can be considered slope parameters in this equation. You may recognize this equation as a special case of the general linear regression equation (see the Multiple Regressionoverview). If the weights for the lagged time periods are statistically significant, we can conclude that the y variable is predicted (or explained) with the respective lag.
i = 0 + 1*i + ... + q*iq
i*xt-i
i) can be considered slope parameters in this equation. You may recognize this equation as a special case of the general linear regression equation (see the Multiple Regressionoverview). If the weights for the lagged time periods are statistically significant, we can conclude that the y variable is predicted (or explained) with the respective lag.
i = 0 + 1*i + ... + q*iq
Single Spectrum (Fourier) Analysis
Cross-spectrum Analysis
Cross-spectrum analysis is an extension of Single Spectrum (Fourier) Analysis to the simultaneous analysis of two series. In the following paragraphs, we will assume that you have already read the introduction to single spectrum analysis. Detailed discussions of this technique can be found in Bloomfield (1976), Jenkins and Watts (1968), Brillinger (1975), Brigham (1974), Elliott and Rao (1982), Priestley (1981), Shumway (1988), or Wei (1989).
Strong periodicity in the series at the respective frequency. A much cited example for spectrum analysis is the cyclical nature of sun spot activity (e.g., see Bloomfield, 1976, or Shumway, 1988). It turns out that sun spot activity varies over 11 year cycles. Other examples of celestial phenomena, weather patterns, fluctuations in commodity prices, economic activity, etc. are also often used in the literature to demonstrate this technique.
The purpose of cross-spectrum analysis is to uncover the correlations between two series at different frequencies. For example, sun spot activity may be related to weather phenomena here on earth. If so, then if we were to record those phenomena (e.g., yearly average temperature) and submit the resulting series to a cross-spectrum analysis together with the sun spot data, we may find that the weather indeed correlates with the sunspot activity at the 11 year cycle. That is, we may find a periodicity in the weather data that is "in-sync" with the sun spot cycles. One can easily think of other areas of research where such knowledge could be very useful; for example, various economic indicators may show similar (correlated) cyclical behavior; various physiological measures likely will also display "coordinated" (i.e., correlated) cyclical behavior, and so on.
Basic Notation and Principles
A simple example
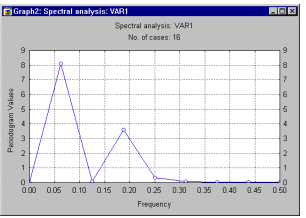
Consider the following two series with 16 cases:
| VAR1 | VAR2 | |
|---|---|---|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
1.000 1.637 1.148 -.058 -.713 -.383 .006 -.483 -1.441 -1.637 -.707 .331 .441 -.058 -.006 .924 |
-.058 -.713 -.383 .006 -.483 -1.441 -1.637 -.707 .331 .441 -.058 -.006 .924 1.713 1.365 .266 |
At first sight it is not easy to see the relationship between the two series. However, as shown below the series were created so that they would contain two strong correlated periodicities. Shown below are parts of the summary from the cross-spectrum analysis (the spectral estimates were smoothed with a Parzen window of width 3).
| Indep.(X): VAR1 Dep.(Y): VAR2 |
||||||
|---|---|---|---|---|---|---|
| Frequncy |
Period |
X Density |
Y Density |
Cross Density |
Cross Quad |
Cross Amplit. |
| 0.000000 .062500 .125000 .187500 .250000 .312500 .375000 .437500 .500000 |
16.00000 8.00000 5.33333 4.00000 3.20000 2.66667 2.28571 2.00000 |
.000000 8.094709 .058771 3.617294 .333005 .091897 .052575 .040248 .037115 |
.024292 7.798284 .100936 3.845154 .278685 .067630 .036056 .026633 0.000000 |
-.00000 2.35583 -.04755 -2.92645 -.26941 -.07435 -.04253 -.03256 0.00000 |
0.00000 -7.58781 .06059 2.31191 .14221 .02622 .00930 .00342 0.00000 |
.000000 7.945114 .077020 3.729484 .304637 .078835 .043539 .032740 0.000000 |
The complete summary contains all spectrum statistics computed for each variable, as described in the Single Spectrum (Fourier) Analysis overview section. Looking at the results shown above, it is clear that both variables show strong periodicities at the frequencies .0625 and .1875.
Cross-periodogram, Cross-Density, Quadrature-density, Cross-amplitude
Analogous to the results for the single variables, the complete summary will also display periodogram values for the cross periodogram. However, the cross-spectrum consists of complex numbers that can be divided into a real and an imaginary part. These can be smoothed to obtain the cross-density and quadrature density (quad density for short) estimates, respectively. (The reasons for smoothing, and the different common weight functions for smoothing are discussed in the Single Spectrum (Fourier) Analysis.) The square root of the sum of the squared cross-density and quad-density values is called the cross- amplitude. The cross-amplitude can be interpreted as a measure of covariance between the respective frequency components in the two series. Thus we can conclude from the results shown in the table above that the .0625 and .1875 frequency components in the two series covary.
Squared Coherency, Gain, and Phase Shift
There are additional statistics that can be displayed in the complete summary.
Squared coherency. One can standardize the cross-amplitude values by squaring them and dividing by the product of the spectrum density estimates for each series. The result is called the squared coherency, which can be interpreted similar to the squared correlation coefficient (see Correlations - Overview), that is, the coherency value is the squared correlation between the cyclical components in the two series at the respective frequency. However, the coherency values should not be interpreted by themselves; for example, when the spectral density estimates in both series are very small, large coherency values may result (the divisor in the computation of the coherency values will be very small), even though there are no strong cyclical components in either series at the respective frequencies.
Gain. The gain value is computed by dividing the cross-amplitude value by the spectrum density estimates for one of the two series in the analysis. Consequently, two gain values are computed, which can be interpreted as the standard least squares regression coefficients for the respective frequencies.
Phase shift. Finally, the phase shift estimates are computed as tan**-1 of the ratio of the quad density estimates over the cross-density estimate. The phase shift estimates (usually denoted by the Greek letter ) are measures of the extent to which each frequency component of one series leads the other.
How the Example Data were Created
Now, let us return to the example data set presented above. The large spectral density estimates for both series, and the cross-amplitude values at frequencies 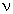 = 0.0625 and = .1875 suggest two strong synchronized periodicities in both series at those frequencies. In fact, the two series were created as:
= 0.0625 and = .1875 suggest two strong synchronized periodicities in both series at those frequencies. In fact, the two series were created as:
v1 = cos(2*
v2 = cos(2* *.0625*(v0-1)) + .75*sin(2**.2*(v0-1))*.0625*(v0+2)) + .75*sin(2**.2*(v0+2))
*.0625*(v0-1)) + .75*sin(2**.2*(v0-1))*.0625*(v0+2)) + .75*sin(2**.2*(v0+2))
(where v0 is the case number). Indeed, the analysis presented in this overview reproduced the periodicity "inserted" into the data very well.
Frequency and Period
The "wave length" of a sine or cosine function is typically expressed in terms of the number of cycles per unit time (Frequency), often denoted by the Greek letter nu ( ; some text books also use f). For example, the number of letters handled in a post office may show 12 cycles per year: On the first of every month a large amount of mail is sent (many bills come due on the first of the month), then the amount of mail decreases in the middle of the month, then it increases again towards the end of the month. Therefore, every month the fluctuation in the amount of mail handled by the post office will go through a full cycle. Thus, if the unit of analysis is one year, then n would be equal to 12, as there would be 12 cycles per year. Of course, there will likely be other cycles with different frequencies. For example, there might be annual cycles ( =1), and perhaps weekly cycles <(=52 weeks per year).
The period T of a sine or cosine function is defined as the length of time required for one full cycle. Thus, it is the reciprocal of the frequency, or: T = 1/. To return to the mail example in the previous paragraph, the monthly cycle, expressed in yearly terms, would be equal to 1/12 = 0.0833. Put into words, there is a period in the series of length 0.0833 years.
The General Structural Model
As mentioned before, the purpose of spectrum analysis is to decompose the original series into underlying sine and cosine functions of different frequencies, in order to determine those that appear particularly strong or important. One way to do so would be to cast the issue as a linear Multiple Regression problem, where the dependent variable is the observed time series, and the independent variables are the sine functions of all possible (discrete) frequencies. Such a linear multiple regression model may be written as:
xt = a0 + [ak*cos(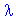 k*t) + bk*sin(k*t)] (for k = 1 to q)
k*t) + bk*sin(k*t)] (for k = 1 to q)
Following the common notation from classical harmonic analysis, in this equation (lambda) is the frequency expressed in terms of radians per unit time, that is: = 2* *k, where is the constant pi=3.14... and k = k/q. What is important here is to recognize that the computational problem of fitting sine and cosine functions of different lengths to the data can be considered in terms of multiple linear regression. Note that the cosine parameters ak and sine parameters bk are regression coefficients that tell us the degree to which the respective functions are correlated with the data. Overall there are q different sine and cosine functions; intuitively (as also discussed in Multiple Regression), it should be clear that we cannot have more sine and cosine functions than there are data points in the series. Without going into detail, if there are N data points in the series, then there will be N/2+1 cosine functions and N/2-1 sine functions. In other words, there will be as many different sinusoidal waves as there are data points, and we will be able to completely reproduce the series from the underlying functions. (Note that if the number of cases in the series is odd, then the last data point will usually be ignored; in order for a sinusoidal function to be identified, you need at least two points: the high peak and the low peak.)
*k, where is the constant pi=3.14... and k = k/q. What is important here is to recognize that the computational problem of fitting sine and cosine functions of different lengths to the data can be considered in terms of multiple linear regression. Note that the cosine parameters ak and sine parameters bk are regression coefficients that tell us the degree to which the respective functions are correlated with the data. Overall there are q different sine and cosine functions; intuitively (as also discussed in Multiple Regression), it should be clear that we cannot have more sine and cosine functions than there are data points in the series. Without going into detail, if there are N data points in the series, then there will be N/2+1 cosine functions and N/2-1 sine functions. In other words, there will be as many different sinusoidal waves as there are data points, and we will be able to completely reproduce the series from the underlying functions. (Note that if the number of cases in the series is odd, then the last data point will usually be ignored; in order for a sinusoidal function to be identified, you need at least two points: the high peak and the low peak.)
To summarize, spectrum analysis will identify the correlation of sine and cosine functions of different frequency with the observed data. If a large correlation (sine or cosine coefficient) is identified, one can conclude that there is a strong periodicity of the respective frequency (or period) in the data.
Complex numbers (real and imaginary numbers). In many text books on spectrum analysis, the structural model shown above is presented in terms of complex numbers, that is, the parameter estimation process is described in terms of the Fourier transform of a series into real and imaginary parts. Complex numbers are the superset that includes all real and imaginary numbers. Imaginary numbers, by definition, are numbers that are multiplied by the constant i, where i is defined as the square root of -1. Obviously, the square root of -1 does not exist, hence the term imaginary number; however, meaningful arithmetic operations on imaginary numbers can still be performed (e.g., [i*2]**2= -4). It is useful to think of real and imaginary numbers as forming a two dimensional plane, where the horizontal or X-axis represents all real numbers, and the vertical or Y-axis represents all imaginary numbers. Complex numbers can then be represented as points in the two- dimensional plane. For example, the complex number 3+i*2 can be represented by a point with coordinates {3,2} in this plane. One can also think of complex numbers as angles, for example, one can connect the point representing a complex number in the plane with the origin (complex number 0+i*0), and measure the angle of that vector to the horizontal line. Thus, intuitively one can see how the spectrum decomposition formula shown above, consisting of sine and cosine functions, can be rewritten in terms of operations on complex numbers. In fact, in this manner the mathematical discussion and required computations are often more elegant and easier to perform; which is why many text books prefer the presentation of spectrum analysis in terms of complex numbers.
A Simple Example
Shumway (1988) presents a simple example to clarify the underlying "mechanics" of spectrum analysis. Let us create a series with 16 cases following the equation shown above, and then see how we may "extract" the information that was put in it. First, create a variable and define it as:
x = 1*cos(2**.0625*(v0-1)) + .75*sin(2**.2*(v0-1))
This variable is made up of two underlying periodicities: The first at the frequency of =.0625 (or period 1/=16; one observation completes 1/16'th of a full cycle, and a full cycle is completed every 16 observations) and the second at the frequency of =.2 (or period of 5). The cosine coefficient (1.0) is larger than the sine coefficient (.75). The spectrum analysis summary are shown below.
| Spectral analysis:VAR1 (shumex.sta) No. of cases: 16 |
|||||
|---|---|---|---|---|---|
| t |
Freq- uency |
Period |
Cosine Coeffs |
Sine Coeffs |
Period- ogram |
| 0 1 2 3 4 5 6 7 8 |
.0000 .0625 .1250 .1875 .2500 .3125 .3750 .4375 .5000 |
16.00 8.00 5.33 4.00 3.20 2.67 2.29 2.00 |
.000 1.006 .033 .374 -.144 -.089 -.075 -.070 -.068 |
0.000 .028 .079 .559 -.144 -.060 -.031 -.014 0.000 |
.000 8.095 .059 3.617 .333 .092 .053 .040 .037 |
Periodogram
The sine and cosine functions are mutually independent (or orthogonal); thus we may sum the squared coefficients for each frequency to obtain the periodogram. Specifically, the periodogram values above are computed as:
Pk = sine coefficientk2 + cosine coefficientk2 * N/2
where Pk is the periodogram value at frequency k and N is the overall length of the series. The periodogram values can be interpreted in terms of variance (sums of squares) of the data at the respective frequency or period. Customarily, the periodogram values are plotted against the frequencies or periods.
The Problem of Leakage
In the example above, a sine function with a frequency of 0.2 was "inserted" into the series. However, because of the length of the series (16), none of the frequencies reported exactly "hits" on that frequency. In practice, what often happens in those cases is that the respective frequency will "leak" into adjacent frequencies. For example, one may find large periodogram values for two adjacent frequencies, when, in fact, there is only one strong underlying sine or cosine function at a frequency that falls in-between those implied by the length of the series. There are three ways in which one can approach the problem of leakage:
Padding the Time Series
Because the frequency values are computed as N/t (the number of units of times) one may simply pad the series with a constant (e.g., zeros) and thereby introduce smaller increments in the frequency values. In a sense, padding allows one to apply a finer roster to the data. In fact, if we padded the example data file described in the example above with ten zeros, the results would not change, that is, the largest periodogram peaks would still occur at the frequency values closest to .0625 and .2. (Padding is also often desirable for computational efficiency reasons; see below.)
Tapering
The so-called process of split-cosine-bell tapering is a recommended transformation of the series prior to the spectrum analysis. It usually leads to a reduction of leakage in the periodogram. The rationale for this transformation is explained in detail in Bloomfield (1976, p. 80-94). In essence, a proportion (p) of the data at the beginning and at the end of the series is transformed via multiplication by the weights:
wt = 0.5*{1-cos[
where m is chosen so that 2*m/N is equal to the proportion of data to be tapered (p).
Data Windows and Spectral Density Estimates
In practice, when analyzing actual data, it is usually not of crucial importance to identify exactly the frequencies for particular underlying sine or cosine functions. Rather, because the periodogram values are subject to substantial random fluctuation, one is faced with the problem of very many "chaotic" periodogram spikes. In that case, one would like to find the frequencies with the greatest spectral densities, that is, the frequency regions, consisting of many adjacent frequencies, that contribute most to the overall periodic behavior of the series. This can be accomplished by smoothing the periodogram values via a weighted moving average transformation. Suppose the moving average window is of width m (which must be an odd number); the following are the most commonly used smoothers (note: p = (m-1)/2).
Daniell (or equal weight) window. The Daniell window (Daniell 1946) amounts to a simple (equal weight) moving average transformation of the periodogram values, that is, each spectral density estimate is computed as the mean of the m/2 preceding and subsequent periodogram values.
Tukey window. In the Tukey (Blackman and Tukey, 1958) or Tukey-Hanning window (named after Julius Von Hann), for each frequency, the weights for the weighted moving average of the periodogram values are computed as:
wj = 0.5 + 0.5*cos( Hamming window. In the Hamming (named after R. W. Hamming) window or Tukey-Hamming window (Blackman and Tukey, 1958), for each frequency, the weights for the weighted moving average of the periodogram values are computed as:
wj = 0.54 + 0.46*cos( Parzen window. In the Parzen window (Parzen, 1961), for each frequency, the weights for the weighted moving average of the periodogram values are computed as:
wj = 1-6*(j/p)2 + 6*(j/p)3 (for j = 0 to p/2) Bartlett window. In the Bartlett window (Bartlett, 1950) the weights are computed as:
wj = 1-(j/p) (for j = 0 to p)
With the exception of the Daniell window, all weight functions will assign the greatest weight to the observation being smoothed in the center of the window, and increasingly smaller weights to values that are further away from the center. In many cases, all of these data windows will produce very similar results
Preparing the Data for Analysis
Let us now consider a few other practical points in spectrum analysis. Usually, one wants to subtract the mean from the series, and detrend the series (so that it is stationary) prior to the analysis. Otherwise the periodogram and density spectrum will mostly be "overwhelmed" by a very large value for the first cosine coefficient (for frequency 0.0). In a sense, the mean is a cycle of frequency 0 (zero) per unit time; that is, it is a constant. Similarly, a trend is also of little interest when one wants to uncover the periodicities in the series. In fact, both of those potentially strong effects may mask the more interesting periodicities in the data, and thus both the mean and the trend (linear) should be removed from the series prior to the analysis. Sometimes, it is also useful to smooth the data prior to the analysis, in order to "tame" the random noise that may obscure meaningful periodic cycles in the periodogram.
Results when no Periodicity in the Series Exists
Finally, what if there are no recurring cycles in the data, that is, if each observation is completely independent of all other observations? If the distribution of the observations follows the normal distribution, such a time series is also referred to as a white noise series (like the white noise one hears on the radio when tuned in-between stations). A white noise input series will result in periodogram values that follow an exponential distribution. Thus, by testing the distribution of periodogram values against the exponential distribution, one may test whether the input series is different from a white noise series. In addition, the you can also request to compute the Kolmogorov-Smirnov one-sample d statistic (see also Nonparametrics and Distributions for more details).
Testing for white noise in certain frequency bands. Note that you can also plot the periodogram values for a particular frequency range only. Again, if the input is a white noise series with respect to those frequencies (i.e., it there are no significant periodic cycles of those frequencies), then the distribution of the periodogram values should again follow an exponential distribution.
*(t - 0.5)/m]}
(for t=0 to m-1)
wt = 0.5*{1-cos[*(N - t + 0.5)/m]}
(for t=N-m to N-1)
*j/p) (for j=0 to p)
w-j = wj (for j  0)
*j/p) (for j=0 to p)
0)
*j/p) (for j=0 to p)
w-j = wj (for j 0)
wj = 2*(1-j/p)3 (for j = p/2 + 1 to p)
w-j = wj (for j 0)
w-j = wj (for j 0)
| To index |
General Introduction
The interpretation of the results of spectrum analysis is discussed in the Basic Notation and Principles topic, however, we have not described how it is done computationally. Up until the mid-1960s the standard way of performing the spectrum decomposition was to use explicit formulae to solve for the sine and cosine parameters. The computations involved required at least N**2 (complex) multiplications. Thus, even with today's high-speed computers , it would be very time consuming to analyze even small time series (e.g., 8,000 observations would result in at least 64 million multiplications).
The time requirements changed drastically with the development of the so-called fast Fourier transform algorithm, or FFT for short. In the mid-1960s, J.W. Cooley and J.W. Tukey (1965) popularized this algorithm which, in retrospect, had in fact been discovered independently by various individuals. Various refinements and improvements of this algorithm can be found in Monro (1975) and Monro and Branch (1976). Readers interested in the computational details of this algorithm may refer to any of the texts cited in the overview. Suffice it to say that via the FFT algorithm, the time to perform a spectral analysis is proportional to N*log2(N) -- a huge improvement.
However, a draw-back of the standard FFT algorithm is that the number of cases in the series must be equal to a power of 2 (i.e., 16, 64, 128, 256, ...). Usually, this necessitated padding of the series, which, as described above, will in most cases not change the characteristic peaks of the periodogram or the spectral density estimates. In cases, however, where the time units are meaningful, such padding may make the interpretation of results more cumbersome.
Computation of FFT in Time Series
The implementation of the FFT algorithm allows you to take full advantage of the savings afforded by this algorithm. On most standard computers, series with over 100,000 cases can easily be analyzed. However, there are a few things to remember when analyzing series of that size.
As mentioned above, the standard (and most efficient) FFT algorithm requires that the length of the input series is equal to a power of 2. If this is not the case, additional computations have to be performed. It will use the simple explicit computational formulas as long as the input series is relatively small, and the number of computations can be performed in a relatively short amount of time. For long time series, in order to still utilize the FFT algorithm, an implementation of the general approach described by Monro and Branch (1976) is used. This method requires significantly more storage space, however, series of considerable length can still be analyzed very quickly, even if the number of observations is not equal to a power of 2.
For time series of lengths not equal to a power of 2, we would like to make the following recommendations: If the input series is small to moderately sized (e.g., only a few thousand cases), then do not worry. The analysis will typically only take a few seconds anyway. In order to analyze moderately large and large series (e.g., over 100,000 cases), pad the series to a power of 2 and then taper the series during the exploratory part of your data analysis.