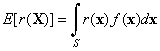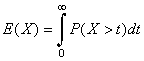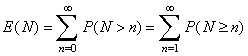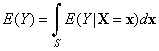Properties of Expected Value |
We now know that the expected value of a random variable gives the center of the distribution of the variable. This idea is much more powerful than might first appear. By finding expected values of various functions of a random vector, we can measure many interesting features of the distribution of the vector.
Thus, suppose that X is a random vector taking values in a subset S of Rn and suppose that r is a function from S into R. Then r(X) is a random variable and we would like to comput E[r(X)]. However, to compute this expected value from the definition would require that we know the density function of r(X) (a difficult problem, in general). Fortunately, there is a much better way, given by the change of variables theorem for expected value.
![]() 1. Show that if X
has a discrete distribution with density function f then
1. Show that if X
has a discrete distribution with density function f then
Similarly, if X has a continuous distribution with density function f then
![]() 2. Prove the continuous version of
the change of variables theorem when r is discrete
(i.e., r has countable range).
2. Prove the continuous version of
the change of variables theorem when r is discrete
(i.e., r has countable range).
![]() 3. Suppose that X has
probability density function
3. Suppose that X has
probability density function
f(x) = x2 / 10 for x in {-2, -1, 0, 1, 2}
Find E[1 / (1 + X2)]
![]() 4. Suppose that X has density
function
4. Suppose that X has density
function
f(x) = x2 / 3 for -1 < x < 2
Find E(X1/3)
![]() 5. Suppose that (X, Y)
has probability density function
5. Suppose that (X, Y)
has probability density function
f(x, y) = (x + y) / 4 for 0 < x < y < 2
Find E(X2Y).
The exercises below gives basic properties of expected value. These properties are true in general, but restrict your proofs to the discrete and continuous cases separately; the change of variables theorem is the main tool you will need. In these exercises X and Y are random variables for an experiment and c is a constant.
![]() 6. Show that E(X + Y)
= E(X) + E(Y)
6. Show that E(X + Y)
= E(X) + E(Y)
![]() 7. Show that E(cX)
= cE(X)
7. Show that E(cX)
= cE(X)
![]() 8. Show that if X
8. Show that if X ![]() 0 then E(X)
0 then E(X)
![]() 0.
0.
![]() 9. Show that if X
9. Show that if X ![]() Y then E(X)
Y then E(X)
![]() E(Y)
E(Y)
![]() 10. Show that |E(X)|
10. Show that |E(X)|
![]() E(|X|)
E(|X|)
The results in Exercises 6-10 are so basic that it is important to understand them on an intuitive level. Indeed, these properties are in some sense implied by the interpretation of expected value given in the law of large numbers.
![]() 11. Suppose that X and Y
are independent. Show that
11. Suppose that X and Y
are independent. Show that
E(XY) = E(X)E(Y)
Exercise 11 shows that independent random variables are uncorrelated.
![]() 12. Suppose that (X, Y)
has density function
12. Suppose that (X, Y)
has density function
f(x, y) = (3 / 2) x2y for 0 < x < 1, 0 < y < 2
Use the result in Exercise 12 to find E[X3(Y2 + 1)].
![]() 13. Let X be a nonnegative
random variable for an experiment. Show that
13. Let X be a nonnegative
random variable for an experiment. Show that
![]() 14. Suppose that X has the
power distribution with parameter a > 1, which has
density function
14. Suppose that X has the
power distribution with parameter a > 1, which has
density function
f(x) = (a - 1)x-a for x > 1
Use the result of Exercise 13 to find E(X).
![]() 15. Use the result of Exercise 13 to
prove Markov's
inequality: If X is a nonnegative random variable, then
for t > 0,
15. Use the result of Exercise 13 to
prove Markov's
inequality: If X is a nonnegative random variable, then
for t > 0,
![]() 16. Compute both sides of the
Markov's inequality when X has the power distribution with
parameter a > 1.
16. Compute both sides of the
Markov's inequality when X has the power distribution with
parameter a > 1.
f(x) = (a - 1)x-a for x > 1
![]() 17. Use the result of Exercise 13 to
prove the change of variables formula when the random vector X
is continuous and r is nonnegative.
17. Use the result of Exercise 13 to
prove the change of variables formula when the random vector X
is continuous and r is nonnegative.
The following result is similar to Exercise 13, but is specialized to nonnegative integer variables:
![]() 18. Suppose that N is a
discrete random variable that takes values in the set of
nonnegative integers. Show that
18. Suppose that N is a
discrete random variable that takes values in the set of
nonnegative integers. Show that
![]() 19. Suppose that N has
density function
19. Suppose that N has
density function
f(n) = (1 - q)qn for n = 0, 1, 2, ...
where q in (0, 1) is a parameter. Use the result of Exercise 18 to find E(N).
If X is a random variable and k is a positive integer, the expected value
E[(X - a)k]
is known as the k'th moment of X about a. When a = E(X), the mean, the moments are called central moments. The second central moment is especially important; it is known as the variance.
Our next sequence of exercises will establish an important inequality known as Jensen's inequality. First we need a definition. A real-valued function g defined on an interval I of R is said to be convex on I if for each t in I, there exist numbers a and b (that may depend on t) such that
at + b = g(t), ax + b
g(x) for x in I
![]() 21. Interpret the conditions in the
convexity definition geometrically (in terms of graphs). The line
y = ax + b is called a supporting
line.
21. Interpret the conditions in the
convexity definition geometrically (in terms of graphs). The line
y = ax + b is called a supporting
line.
You may be more familiar with convexity in terms of the following theorem from calculus:
![]() 22. Show that g is convex on I
if g is twice differentiable on I and has
non-negative second derivative on I. Hint: Show that for
each t in I, the tangent line at t is a
supporting line.
22. Show that g is convex on I
if g is twice differentiable on I and has
non-negative second derivative on I. Hint: Show that for
each t in I, the tangent line at t is a
supporting line.
![]() 23. Prove Jensen's inequality:
If X takes values in an interval I and g is
convex on I, then
23. Prove Jensen's inequality:
If X takes values in an interval I and g is
convex on I, then
E[g(X)]
g[E(X)]
Hint: In the definition of convexity given above, let t = E(X) and replace x with X. Then take expected values through the inequality.
The expected value of a random variable X is based, of course, on the probability measure P for the experiment. This probability measure could be a conditional probability measure, conditioned on a given event B for the experiment (with P(B) > 0). The usual notation is E(X | B), and this expected value is computed by the definition given above, except that the conditional density f(x | B) replaces the ordinary density f(x). It is very important to realize that, except for notation, no new concepts are involved. The results we have established for expected value in general have analogues for these conditional expected values.
![]() 24. Suppose that X has
probability density function
24. Suppose that X has
probability density function
f(x) = x2 / 3 for -1 < x < 2
Find E(X | X > 0).
![]() 25. Suppose that (X, Y)
has probability density function
25. Suppose that (X, Y)
has probability density function
f(x, y) = (x + y) / 4 for 0 < x < y < 2
Find E(XY | Y > 2X).
Now suppose that X is a random vector taking values in a subset S of Rn and Y a random variables. Then
E(Y | X = x)
simply means the expected value computed relative to the conditional distribution of Y given X = x. For fixed x, this expected value satisfies all properties of expected value generally. Moreover, it is the best predictor of Y, in a certain sense, given that X = x.
![]() 26. In the setting above, prove the
following version of the law of total probability:
26. In the setting above, prove the
following version of the law of total probability:
If X has a continuous distribution with density funciton f then
Expected Value |