
В тази лекция си поставяме следните цели
Полиномният модел може да се запише във формата:
| (10.1) |
Ще разгледаме един пример. Числата 75.995 91.972 105.711 123.203 131.669 150.697 179.323 203.212 226.505, са публикувани от Американския статистически институт и представляват населението (в милиони хора) на САЩ за периода от 1900 до 1980 г. Нека си поставим за задача да прогнозираме населението за две последователни десетилетия напред - 1990 и 2000. Като базисен ще разгледаме модела (10.1). Ясно е, че ще трябва да се ограничим с n Ј 8, тъй като разполагаме с 9 наблюдения и последния полином става интерполиращ.
За конкретния случай матрицата X изглежда така:
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 |
| 1 | 3 | 9 | 27 | 81 | 243 | 729 | 2187 | 6561 |
| 1 | 4 | 16 | 64 | 256 | 1024 | 4096 | 16384 | 65536 |
| 1 | 5 | 25 | 125 | 625 | 3125 | 15625 | 78125 | 390625 |
| 1 | 6 | 36 | 216 | 1296 | 7776 | 46656 | 279936 | 1679616 |
| 1 | 7 | 49 | 343 | 2401 | 16807 | 117649 | 823543 | 5764801 |
| 1 | 8 | 64 | 512 | 4096 | 32768 | 262144 | 2097152 | 16777216 |
Оценката (8.4) XўX [^(a)] = Xўy се получава като решение на системата уравнения:
| |||||||||||||||||||||||||||||||||||||||||||||||||||
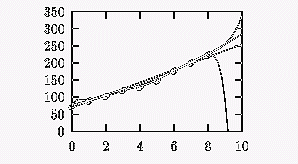
На фигурата 10.2 са представени оригиналните данни, заедно с няколко регресионни полинома - от степени 1,2,6,8. Най-очевидно е несъответствието на прогнозираната стойност за полинома от 8 степен, който предсказва изчезване на цялото население на САЩ преди 2000 г. Пресмятанията са вършени с двойна точност така, че на резултатите от изчисленията може да се вярва. На долните таблици ще видим най - същественото от тези числени сметки. Главната цел, обаче е да въведем математическия апарат, който ще ни помогне да изберем ''оптималния'' от тези полиноми.
|
Определение 1 Казваме, че два полинома са ортогонални (P^Q), ако (P,Q) = 0.
Теорема 1
Ще построим конструктивно редица от ортогонални полиноми:
P0(x) = 1, P1(x) = x-[`(x)], а всички останали
(при n < N) със
следната рекурентна формула:
Pn(x) = (x-an) Pn-1(x) + bn Pn-2(x). (10.2)
Доказателство: Да отбележим, че (P0,P1) = 0. Ще покажем първо, как може да се определят числата an,bn.
|
|
|
| |||||||||||||||||||||||
|
Така построената редица има смисъл, разбира се, докато степента на полинома е малка по сравнение с броя на данните N. Не е трудно да се провери, че Pj, j і N-1 има за корени числата xi.
Сега моделът (10.1) може да се препише във формата:
| (10.5) |
Матрицата XўX за този модел е диагонална и съдържа числата dii = еPi-12(xi).
За нашия случай матрицата X изглежда така (това са стойностите на ортогоналните полиноми върху данните):
| P0 | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 |
| 1 | -4 | 9.3333 | -16.8 | 24.0000 | -26.6667 | 21.8182 | -11.7483 | 3.1329 |
| 1 | -3 | 2.3333 | 8.4 | -36.0000 | 73.3333 | -92.7273 | 70.4895 | -25.0629 |
| 1 | -2 | -2.6667 | 15.6 | -18.8571 | -26.6667 | 120.0000 | -164.4755 | 87.7203 |
| 1 | -1 | -5.6667 | 10.8 | 15.4286 | -60.0000 | 5.4545 | 164.4755 | -175.4406 |
| 1 | 0 | -6.6667 | -0.0 | 30.8571 | 0.0000 | -109.0909 | -0.0000 | 219.3007 |
| 1 | 1 | -5.6667 | -10.8 | 15.4286 | 60.0000 | 5.4545 | -164.4755 | -175.4406 |
| 1 | 2 | -2.6667 | -15.6 | -18.8571 | 26.6667 | 120.0000 | 164.4755 | 87.7203 |
| 1 | 3 | 2.3333 | -8.4 | -36.0000 | -73.3333 | -92.7273 | -70.4895 | -25.0629 |
| 1 | 4 | 9.3333 | 16.8 | 24.0000 | 26.6667 | 21.8182 | 11.7483 | 3.1329 |
Коефициентите на ортогоналните полиноми са показани в следната таблица (редовете са степени на полинома (0 - 8 ), на диагонала е коефициентът пред максималната степен):
| 1. | ||||||||
| -4. | 1. | |||||||
| 9.333 | - 8. | 1. | ||||||
| -16.8 | 36.2 | -12. | 1. | |||||
| 24.0 | -124.57 | 79.5714 | -16. | 1. | ||||
| -26.666 | 372.88 | -393.33 | 139.44 | -20. | 1. | |||
| 21.818 | -1077.82 | 1664.91 | -894.55 | 215.91 | -24. | 1. | ||
| -11.748 | 3277.01 | -6623.468 | 4848.16 | -1701.53 | 309.077 | -28. | 1. | |
| 3.132 | -10953.08 | 26423.99 | -24217.85 | 11220.28 | -2889.6 | 419.067 | -32. | 1. |
Коефициентите на разлагането на отклика bk по този нов базис са дадени в последната таблица.
| ||||||||||||||||||||||||||
|
|
От тези равенства следват и търсените формули:
| |||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
В долната таблица са изведени данните, необходими за намирането на ''оптималния'' полином за нашия пример. В последната колона за удобство са поставени критичните стойности за съответното F-разпределение. Вижда се, че максималната статистически значима степен е 2.
| bk | [(b)\tilde]k2 | F-value | Df | F0.95 | |
| P0 | 143.143 | 184409.3 | 61.525 | 1 8 | 5.32 |
| P1 | 18.508 | 20552.7 | 287.8528 | 1 7 | 5.59 |
| P2 | 1.04582 | 336.87 | 18.358 | 1 6 | 5.98 |
| P3 | .104426 | 15.546 | 0.81392 | 1 5 | 6.60 |
| P4 | -.07695 | 34.838 | 2.52819 | 1 4 | 7.70 |
| P5 | -.02555 | 13.575 | 0.97661 | 1 3 | 10.13 |
| P6 | .00955 | 5.373 | 0.479701 | 1 2 | 18.51 |
| P7 | .01277 | 19.31 | 6.23907 | 1 1 | 161.45 |
| P8 | -.00495 | 3.095 |
От същата таблица се вижда също, че никаква статистическа проверка не е възможна за интерполационния полином от 8 степен. С указаните данни изобщо не е възможна проверка на адекватността на регресионния модел (с полином от 2-ра степен), така че използуването му за прогноза едва ли е оправдано.
Числата от последната колона са взети от таблица на квантилите на F-разпределение. Те се използуват за да се сравнят с тях стойностите на съответните статистики, дадени в колона 3. Когато става въпрос за програми, пресмятането на квантили е обикновено по - трудно от пресмятането на ф.р. Затова обикновено е автоматизирано пресмятането на вероятността: an = P (x < fn) , (x е сл.в. със съответното разпределение). Тя носи названието F - probability и така лесно можем да проверим за дадено ниво на доверие (например, a = 0.95) дали съответната хипотеза се отхвърля. Правилото за избор на оптимална степен съответно става: n = max{k: ak > a}.