Коефициент на детерминация или проверка на наличието на линейна връзка между X и y.
Нека разгледаме сега регресионен модел със свободен член:
| (9.1) |
Нека е вярна хипотезата Ho: a = 0. Естествената контра хипотеза е H1: a № 0. Следователно, Z0 има размерност k = 1, а Z1 е с размерност m = dim(a)+1. От теорема 8.2 получаваме, че критичната област за проверка на хипотезата H0: z О Z0 срещу хипотезата H1:z О Z1\Z0 се определя от неравенството:
|
В приложната статистика съответните суми от квадрати имат популярни наименования, разкриващи тяхната роля в тази проверка:
|
|
Частното
|
Нека е вярна хипотезата H0: a1 = 0. Естествената контра хипотеза е H1: a1 № 0. Следователно, Z0 има размерност k = dim(a)-1 , а Z1 - размерност m = dim(a). От теорема 8.2 получаваме, че оптималната критична област за проверка H0: z О Z0 срещу хипотезата H1:z О Z1\Z0 се определя от неравенството:
|
| (9.2) |
Изведете строго разпределението на статистиките (9.2).
За произволни стойности x на предикторите от областта, за която е верен модела (9.1), случайната величина [^(y)] = xў[^(a)]+[^(b)] е неизместена оценка за E (y | x) и
| (9.3) |
Тук с [`(X)] сме означили вектора 1/nXўE и E е (n xm) матрица от единици, а с [(X)\tilde] сме означили матрицата от центрирани данни (с извадена средна стойност). Следователно, грешката на прогнозираната стойност на конкретното наблюдение ще бъде
| (9.4) |
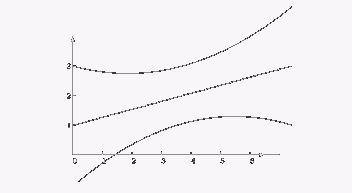
На фигурата е нарисувана апроксимиращата права при простия линеен модел y = ax+b+e. С двете параболи са отбелязани доверителните граници за наблюдаваната стойност съгласно формула (9.4). С аналогична форма, но значително по - тесен е коридорът за модела - формула (9.3). Така се вижда колко опасни (и понякога безсмислени) могат да бъдат прогнози за далечното бъдеще, основани на тенденция, наблюдавана в краен интервал от време.
Проверката за адекватност на модела в регресионния анализ е възможна само в два случая: ако е известна s2 или ако разполагаме с независима от SSR и от параметрите на модела нейна оценка.
В първия случай можем да пресметнем статистиката SSR, която има разпределение s2c2 със степени на свобода n-m, ако моделът е адекватен, и отместено надясно разпределение при неадекватен модел. Така проверката е лесна - критичната област се определя от неравенството:
|
Във втория случай, когато не знаем s2, се налага да използуваме някоя нейна оценка.
Най-популярния начин за получаване на независима оценка за s2 е да се провеждат повторни наблюдения при фиксирани стойности на предикторите. При такива наблюдения сумата SSR също се разлага на две независими събираеми, от които се конструира статистика, която има разпределение на Фишер, в случай че моделът е адекватен. Обикновено тази задача се решава със средствата на еднофакторния дисперсионен анализ. Отделните експериментални точки x се разглеждат като нива на фактор (групираща променлива). За всяко x имаме по nx наблюдения yi(x). Имаме равенството:
| (9.5) |
|
Опишете подпространствата Z0 и Z1 в този случай и изведете уравнение (9.5). Постройте критичната област.