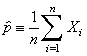Estimating Probabilities and Proportions |
Simulation of the mean estimation experiment
Suppose that the random variable X of interest in our basic experiment is an indicator variable. Thus, by definition, X takes only the values 0 and 1 with probabilities
P(X = 0) = 1 - p, P(X = 1) = p
where p in [0, 1] is a parameter. The distribution of X is known as the Bernoulli distribution with parameter p.
![]() 1. Show that the mean and variance are given by
1. Show that the mean and variance are given by
If p is unknown, then by Exercise 1.a, the problem of estimating p is a special case of the more general problem of estimating an unknown mean.
The problem of estimating the unknown parameter p in a Bernoulli distribution is important enough to warrant its own section. The problem usually arises in terms of one of the following models:
In some cases, the estimation problem can be interpreted in both ways. Here are some concrete examples:
Recall that our main assumption is that we repeat the basic experiment n times to generate a random sample of size n from the distribution of X:
(X1, X2, ..., Xn)
By definition, these are independent variables, each with the same Bernoulli distribution as X.
In the case of model 2 above, the sample variables will be independent if we are sampling with replacement. In practice, of course, we usually sample without replacement, but in this case the sample variables are dependent. It turns out that the independence assumption is satisfied reasonably well if the population size is very large compared to the sample size. For more on these points, see the discussion of the Ball and Urn Experiment.
When estimating the parameter p in the Bernoulli distribution, it is customary to denote the sample mean by
instead of the usual bar notation. In the context of model 1, the sample mean can be interpreted as the relative frequency of the event of interest. In the context of model 2, the sample mean can be interpreted as the sample proportion of objects of the type of interest.
![]() 2. Show that the sum X1
+ X2 + ··· + Xn
in the sample mean has the binomial distribution with parameters n
and p.
2. Show that the sum X1
+ X2 + ··· + Xn
in the sample mean has the binomial distribution with parameters n
and p.
If n is large, our normal procedure of Section 2 usually gives good, approximate confidence intervals for p. However, by Exercise 1.b, it is never realistic to assume that the distribution standard deviation is known, so we must use the sample standard deviation.
![]() 3. Show that in our new notation, the
confidence bounds for p have the form
3. Show that in our new notation, the
confidence bounds for p have the form
where, as usual,
In the following exercises, we can explore the estimation procedure empirically. Make sure that Use S and Use z are selected in the list boxes. This ensures that the simulation will construct the confidence bounds given in Exercise 3.
![]() 4. In the mean estimation experiment, select the
Bernoulli distribution with p = 0.5. Select two-sided
interval and confidence level 0.90. For each of the following
sample sizes, run the experiment 1000 times with an update
frequency of 10. Note how well the proportion of successful
intervals approximates the theoretical confidence level.
4. In the mean estimation experiment, select the
Bernoulli distribution with p = 0.5. Select two-sided
interval and confidence level 0.90. For each of the following
sample sizes, run the experiment 1000 times with an update
frequency of 10. Note how well the proportion of successful
intervals approximates the theoretical confidence level.
![]() 5. In the mean estimation experiment, select the
Bernoulli distribution with p = 0.8. Select lower bound
and confidence level 0.80. For each of the following sample
sizes, run the experiment 1000 times with an update frequency of
10. Note how well the proportion of successful intervals
approximates the theoretical confidence level.
5. In the mean estimation experiment, select the
Bernoulli distribution with p = 0.8. Select lower bound
and confidence level 0.80. For each of the following sample
sizes, run the experiment 1000 times with an update frequency of
10. Note how well the proportion of successful intervals
approximates the theoretical confidence level.
![]() 6. In the mean estimation experiment, select the
Bernoulli distribution with p = 0.1. Select upper bound
and confidence level 0.60. For each of the following sample
sizes, run the experiment 1000 times with an update frequency of
10. Note how well the proportion of successful intervals
approximates the theoretical confidence level.
6. In the mean estimation experiment, select the
Bernoulli distribution with p = 0.1. Select upper bound
and confidence level 0.60. For each of the following sample
sizes, run the experiment 1000 times with an update frequency of
10. Note how well the proportion of successful intervals
approximates the theoretical confidence level.
Computer simulations allow us to explore procedures that are in practice impossible, such as estimating p assuming that the distribution standard deviation is known. For the following exercise, select Use Sigma and Use z quantiles. The simulation will generate confidence bounds of the form
where z is the appropriate quantile as defined in equations 1, 2, and 3 above.
![]() 7. In the mean estimation experiment, select the
Bernoulli distribution with p = 0.5. Select two-sided
interval and confidence level 0.90. For each of the following
sample sizes, run the experiment 1000 times with an update
frequency of 10. Note how well the proportion of successful
intervals approximates the theoretical confidence level and
compare with Exercise 4.
7. In the mean estimation experiment, select the
Bernoulli distribution with p = 0.5. Select two-sided
interval and confidence level 0.90. For each of the following
sample sizes, run the experiment 1000 times with an update
frequency of 10. Note how well the proportion of successful
intervals approximates the theoretical confidence level and
compare with Exercise 4.
![]() 8. Show that the variance of the
Bernoulli distribution is maximized when p = 1/2 and
thus the maximum variance is 1/4.
8. Show that the variance of the
Bernoulli distribution is maximized when p = 1/2 and
thus the maximum variance is 1/4.
![]() 9. Use the result of Exercise 8 to
show that the following formula gives a conservative confidence
bound for p:
9. Use the result of Exercise 8 to
show that the following formula gives a conservative confidence
bound for p:
where z is the appropriate quantile, as defined in equations 1, 2, and 3 above.
Thus, the confidence intervals using the bounds in Exercise 9 will be larger than the confidence intervals using the standard bounds in Exercise 3 or the intervals using the artificial confidence bounds in Exercise 7.
![]() 10. In the mean estimation experiment, select Use
S and select the Bernoulli distribution with p =
0.5. Select two-sided interval, confidence level 0.90, and sample
size n = 30. Run the experiment 100 times, updating
after each run. Now for each run, compute the conservative
confidence interval as in Exercise 9 and compare with the
confidence interval generated by the simulation.
10. In the mean estimation experiment, select Use
S and select the Bernoulli distribution with p =
0.5. Select two-sided interval, confidence level 0.90, and sample
size n = 30. Run the experiment 100 times, updating
after each run. Now for each run, compute the conservative
confidence interval as in Exercise 9 and compare with the
confidence interval generated by the simulation.
Interval Estimation |