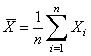Estimating the Mean with Known Variance |
Simulation of the mean estimation experiment
In this section, we will assume that the underlying distribution is normal with mean and standard deviation denoted, as ususal by
We will construct confidence intervals for the mean assuming that the standard deviation is known. It is natural to start with the sample mean
since this statistic is an unbiased estimator of the distribution mean. The crucial fact that we will need is given in the following exercise:
![]() 1. Use properties of the normal
distribution to show that the standard score
1. Use properties of the normal
distribution to show that the standard score
has a standard normal distribution.
Now, for a number p in (0, 1), we will let zp denote the p'th quantile of the standard normal distribution, so that
P(Z < zp) = p.
For selected values of p, values of these quantiles are given in the last row of the table of the t distribution. You could also find the quantiles by using the table of the standard normal distribution.
![]() 2. Use the result of Exercise 1
to show that
2. Use the result of Exercise 1
to show that
![]() 3. Show that the
expression in Exercise 2 can equivalently be written as
3. Show that the
expression in Exercise 2 can equivalently be written as
From Exercise 3, it follows that
is a 1 - a confidence interval for the distribution mean. Note that this interval is symmetric with respect to the sample mean.
![]() 4. Use a derivation similar to
Exercises 2 and 3 to show that a 1 - a confidence lower
bound for the distribution mean is
4. Use a derivation similar to
Exercises 2 and 3 to show that a 1 - a confidence lower
bound for the distribution mean is
![]() 5. Use a derivation similar to
Exercises 2 and 3 to show that a 1 - a confidence upper
bound for the distribution mean is
5. Use a derivation similar to
Exercises 2 and 3 to show that a 1 - a confidence upper
bound for the distribution mean is
Note that the assumption that s is known is critical because, by definition, the confidence bounds cannot contain unknown parameters.
The applet for this page is a simulation of the random experiment of constructing a confidence interval for the mean of a distribution. You can choose among several 2-parameter families of distributions:
The default distribution is the standard normal distribution.
The graph of the density function of the chosen distribution is displayed in the picture box on the left, and the mean is shown as a vertical blue line on the horizontal axis. The mean and standard deviation of the chosen distribution are recorded in the first table on the left.
You can choose among several different confidence levels with a list box: 0.60, 0.80, 0.90, and 0.95. You can choose among several sample sizes with a scroll bar: 5, 10, 15, 20, 25, and 30. You can choose whether to construct a two-sided confidence interval, a confidence lower bound, or a confidence upper bound from a list box.
When you run the simulation, a sample of the specified size is chosen from the given distribution. The sample values are recorded in the second table and the empirical density of the sample is shown in red in the graph on the left. The sample mean and standard deviation are shown in the first table, and when the variable is discrete, the empirical density is also recorded in the first table. The confidence interval is recorded in the third table and is shown graphically as a horizontal red bar in the first graph.
When the confidence interval contains the mean, we have been successful in our estimate and when the confidence interval does not contain the mean, we have failed. An indicator variable I keeps track of our successes and failures. The value of I is recorded on each update in the third table, and the empirical distribution of I is shown in the last graph and last table. By the very meaning of the confidence interval, the relative frequency of successes should be close to the confidence level after a large number of runs.
Make sure that Use Sigma and Use z are selected. The density of the standard normal distribution is shown in the second graph. The quantiles are recorded and the interval defined by the quantiles are shown as a blue bar below the axis of the middle graph.
When you run the simulation, the value of the standard score Z is recorded in the third table and shown as a vertical red line in the middle graph. The event that the standard score falls in the critical interval is equivalent to the event that the confidence interval successfully captured the mean (and thus the success indicator variable I takes the value 1).
The mean estimation experiment displays other information which will be explained as we develop the theory. First, however, let us experience some confidence intervals.
![]() 6. In the mean estimation experiment, select the
normal distribution with mean 0 and standard deviation 2, and
select two-sided intervals. For each of the following sample
sizes and confidence levels, run the experiment 1000 times with
an update frequency of 10. Note the size and location of the
confidence intervals an how well the proportion of successful
intervals approximates the theoretical confidence level.
6. In the mean estimation experiment, select the
normal distribution with mean 0 and standard deviation 2, and
select two-sided intervals. For each of the following sample
sizes and confidence levels, run the experiment 1000 times with
an update frequency of 10. Note the size and location of the
confidence intervals an how well the proportion of successful
intervals approximates the theoretical confidence level.
![]() 7. In the interval estimate experiment, select
the normal distribution with mean 0 and standard deviation 2 and
select lower bound. For each of the following sample sizes and
confidence levels, run the experiment 1000 times with an update
frequency of 10. Note the size and location of the confidence
intervals an how well the proportion of successful intervals
approximates the theoretical confidence level.
7. In the interval estimate experiment, select
the normal distribution with mean 0 and standard deviation 2 and
select lower bound. For each of the following sample sizes and
confidence levels, run the experiment 1000 times with an update
frequency of 10. Note the size and location of the confidence
intervals an how well the proportion of successful intervals
approximates the theoretical confidence level.
![]() 8. In the interval estimate experiment, select
the normal distribution with mean 0 and standard deviation 0.5
and select upper bound. For each of the following sample sizes
and confidence levels, run the experiment 1000 times with an
update frequency of 10. Note the size and location of the
confidence intervals an how well the proportion of successful
intervals approximates the theoretical confidence level.
8. In the interval estimate experiment, select
the normal distribution with mean 0 and standard deviation 0.5
and select upper bound. For each of the following sample sizes
and confidence levels, run the experiment 1000 times with an
update frequency of 10. Note the size and location of the
confidence intervals an how well the proportion of successful
intervals approximates the theoretical confidence level.
In Exercises 6, 7, and 8, you should have noticed the general behavior described in the following exercise:
![]() 9. Show that the confidence interval
(either two-sided or one-sided)
9. Show that the confidence interval
(either two-sided or one-sided)
In particular, Exercise 9.b shows that there is a tradeoff between the confidence level and the size of the confidence interval. If the sample size and standard deviation are fixed, we can decrease the size of our interval, and hence tighten our estimate, only at the expense of decreasing our confidence in the estimate. Conversely, we can increase our confidence in the estimate only at the expense of enlarging the size of our interval.
Again, our two crucial assumptions are that the underlying distribution is normal with known standard deviation. You should question the legitimacy of both assumptions. First, of course, in real estimation problems, we are unlikely to know much about the underlying distribution, let alone whether or not it is normal.
Moreover, the assumption that the mean of the underlying distribution is unknown, but the variance is known, is usually artificial. However, this is not always the case. Suppose, for example, that we have a machine that is designed to produce parts of a specified length. Because of imperfections in the process however, the true length of a part will be a random variable. The variance of the distribution may be due to inherent factors in the machine, which may remain fairly stable over time. In this case, the variance may known from historical data to a high degree of accuracy. The mean, on the other hand, may be set by adjusting the machine and hence may change to an unknown value fairly frequently because of vibrations or other factors.
In any event, most of the rest of this chapter is devoted to the study of confidence intervals for the mean when our assumptions are relaxed.
Interval Estimation |