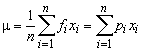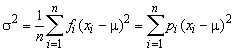Mean and Standard Deviation |
Interactive histogram with mean and standard deviation
Recall also that in our general notation, we have a data set with n points arranged in a frequency distribution with k classes. The class mark of the i'th class is denoted xi; the frequency of the i'th class is denoted fi and the relative frequency of th i'th class is denoted pi = fi / n.
The mean of a data set is simply the arithmetic average of the values in the set, obtained by summing the values and dividing by the number of values. Recall that when we summarize a data set in a frequency distribution, we are approximating the data set by "rounding" each value in a given class to the class mark. With this in mind, it is natural to define the mean of a frequency distribution by
The mean is a measure of the center of the distribution. As you can see from the algebraic formula, the mean is a weighted average of the class marks, with the relative frequencies as the weight factors. We can compare the distribution to a mass distribution, by thinking of the class marks as point masses on a wire (the x-axis) and the relative frequencies as the masses of these points. In this analogy, the mean is literally the center of mass--the balance point of the wire.
Recall also that we can think of the relative frequency distribution as the probability distribution of a random variable X that gives the mark of the class containing a randomly chosen value from the data set. With this interpretation, the mean of the frequency distribution is the same as the mean (or expected value) of X.
The variance of a data set is the arithmetic average of the squared differences between the values and the mean. Again, when we summarize a data set in a frequency distribution, we are approximating the data set by "rounding" each value in a given class to the class mark. Thus, the variance of a frequency distribution is given by
The standard deviation is the square root of the variance:
The variance and the standard deviation are both measures of the spread of the distribution about the mean. The variance is the nicer of the two measures of spread from a mathematical point of view, but as you can see from the algebraic formula, the physical unit of the variance is the square of the physical unit of the data. For example, if our variable represents the weight of a person in pounds, the variance measures spread about the mean in squared pounds. On the other hand, standard deviation measures spread in the same physical unit as the original data, but because of the square root, is not as nice mathematically. Both measures of spread are useful.
Again we can think of the relative frequency distribution as the probability distribution of a random variable X that gives the mark of the class containing a randomly chosen value from the data set. With this interpretation, the variance and standard deviation of the frequency distribution are the same as the variance and standard deviation of X.
As before, you can construct a frequency distribution and histogram for a continuous variable x by clicking on the horizontal axis from 0.1 to 5.0. You can select class width 0.1 with 50 classes, or width 0.2 with 25 classes, or width 0.5 with 10 classes, or width 1.0 with 5 classes, or width 5.0 with 1 class. The mean, variance, and standard deviation are recorded numerically in the second table. The mean and standard deviation are shown graphically as the horizontal red bar below the x-axis. This bar is centered at the mean and extends one standard deviation on either side.
![]() 1. In the applet, set the class
width to 0.1 and construct a frequency distribution with at least
6 nonempty classes and at least 10 values. Compute the min, max,
mean, variance, and standard deviation by hand, and verify that
you get the same results as the applet.
1. In the applet, set the class
width to 0.1 and construct a frequency distribution with at least
6 nonempty classes and at least 10 values. Compute the min, max,
mean, variance, and standard deviation by hand, and verify that
you get the same results as the applet.
![]() 2. In the applet, set the class
width to 0.1 and construct a distribution with at least 30 values
of each of the types indicated below. Then increase the class
width to each of the other four values. As you perform these
operations, note the position and size of the mean ± standard
deviation bar.
2. In the applet, set the class
width to 0.1 and construct a distribution with at least 30 values
of each of the types indicated below. Then increase the class
width to each of the other four values. As you perform these
operations, note the position and size of the mean ± standard
deviation bar.
![]() 3. Based on your experiments,
answer the following questions:
3. Based on your experiments,
answer the following questions:
![]() 4. By experimentation, construct a
distribution with the smallest possible standard deviation.
4. By experimentation, construct a
distribution with the smallest possible standard deviation.
![]() 5. Based on your result in Exercise
4, characterize the distributions with the smallest possible
standard deviation.
5. Based on your result in Exercise
4, characterize the distributions with the smallest possible
standard deviation.
![]() 6. In the applet, construct a
distribution that has the largest possible standard deviation.
6. In the applet, construct a
distribution that has the largest possible standard deviation.
![]() 7. Based on your answer to problem
6, characterize the distributions (on a fixed interval [a,
b]) that have the largest possible standard deviation.
7. Based on your answer to problem
6, characterize the distributions (on a fixed interval [a,
b]) that have the largest possible standard deviation.
![]() 8. In each case below, start with a
distribution that satisfies
8. In each case below, start with a
distribution that satisfies
Add one additional point as described and note the effect on the mean ± standard deviation bar:
In Exercise 8, you should have noticed that the mean and standard deviation changed in each case. In general, these measures are sensitive to changes in the data.
Descriptive Statistics |