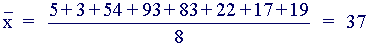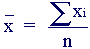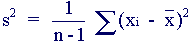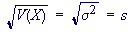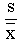|
Presenting data
 Discrete Data
Discrete Data
A set of data is said to be discrete if the values / observations belonging to it are distinct and separate, i.e. they can be counted (1,2,3,....). Examples might include the number of kittens in a litter; the number of patients in a doctors surgery; the number of flaws in one metre of cloth; gender (male, female); blood group (O, A, B, AB). Compare continuous data.
Categorical Data
A set of data is said to be categorical if the values or observations belonging to it can be sorted according to category. Each value is chosen from a set of non-overlapping categories. For example, shoes in a cupboard can be sorted according to colour: the characteristic 'colour' can have non-overlapping categories 'black', 'brown', 'red' and 'other'. People have the characteristic of 'gender' with categories 'male' and 'female'. Categories should be chosen carefully since a bad choice can prejudice the outcome of an investigation. Every value should belong to one and only one category, and there should be no doubt as to which one.
Nominal Data
A set of data is said to be nominal if the values / observations belonging to it can be assigned a code in the form of a number where the numbers are simply labels. You can count but not order or measure nominal data. For example, in a data set males could be coded as 0, females as 1; marital status of an individual could be coded as Y if married, N if single.
Ordinal Data
A set of data is said to be ordinal if the values / observations belonging to it can be ranked (put in order) or have a rating scale attached. You can count and order, but not measure, ordinal data. The categories for an ordinal set of data have a natural order, for example, suppose a group of people were asked to taste varieties of biscuit and classify each biscuit on a rating scale of 1 to 5, representing strongly dislike, dislike, neutral, like, strongly like. A rating of 5 indicates more enjoyment than a rating of 4, for example, so such data are ordinal. However, the distinction between neighbouring points on the scale is not necessarily always the same. For instance, the difference in enjoyment expressed by giving a rating of 2 rather than 1 might be much less than the difference in enjoyment expressed by giving a rating of 4 rather than 3.
Interval Scale
An interval scale is a scale of measurement where the distance between any two adjacents units of measurement (or 'intervals') is the same but the zero point is arbitrary. Scores on an interval scale can be added and subtracted but can not be meaningfully multiplied or divided. For example, the time interval between the starts of years 1981 and 1982 is the same as that between 1983 and 1984, namely 365 days. The zero point, year 1 AD, is arbitrary; time did not begin then. Other examples of interval scales include the heights of tides, and the measurement of longitude.
Continuous Data
A set of data is said to be continuous if the values / observations belonging to it may take on any value within a finite or infinite interval. You can count, order and measure continuous data. For example height, weight, temperature, the amount of sugar in an orange, the time required to run a mile. Compare discrete data.
Frequency Table
A frequency table is a way of summarising a set of data. It is a record of how often each value (or set of values) of the variable in question occurs. It may be enhanced by the addition of percentages that fall into each category. A frequency table is used to summarise categorical, nominal, and ordinal data. It may also be used to summarise continuous data once the data set has been divided up into sensible groups. When we have more than one categorical variable in our data set, a frequency table is sometimes called a contingency table because the figures found in the rows are contingent upon (dependent upon) those found in the columns.
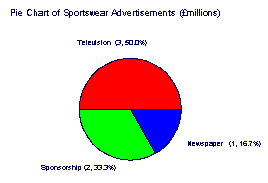
Pie Chart
A pie chart is a way of summarising a set of categorical data. It is a circle which is divided into segments. Each segment represents a particular category. The area of each segment is proportional to the number of cases in that category.
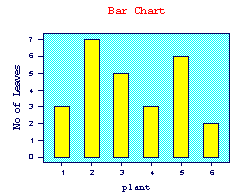
Bar Chart
A bar chart is a way of summarising a set of categorical data. It is often used in exploratory data analysis to illustrate the major features of the distribution of the data in a convenient form. It displays the data using a number of rectangles, of the same width, each of which represents a particular category. The length (and hence area) of each rectangle is proportional to the number of cases in the category it represents, for example, age group, religious affiliation. Bar charts are used to summarise nominal or ordinal data. Bar charts can be displayed horizontally or vertically and they are usually drawn with a gap between the bars (rectangles), whereas the bars of a histogram are drawn immediately next to each other.
Dot Plot
A dot plot is a way of summarising data, often used in exploratory data analysis to illustrate the major features of the distribution of the data in a convenient form. For nominal or ordinal data, a dot plot is similar to a bar chart, with the bars replaced by a series of dots. Each dot represents a fixed number of individuals. For continuous data, the dot plot is similar to a histogram, with the rectangles replaced by dots. A dot plot can also help detect any unusual observations (outliers), or any gaps in the data set.
Histogram
A histogram is a way of summarising data that are measured on an interval scale (either discrete or continuous). It is often used in exploratory data analysis to illustrate the major features of the distribution of the data in a convenient form. It divides up the range of possible values in a data set into classes or groups. For each group, a rectangle is constructed with a base length equal to the range of values in that specific group, and an area proportional to the number of observations falling into that group. This means that the rectangles might be drawn of non-uniform height. The histogram is only appropriate for variables whose values are numerical and measured on an interval scale. It is generally used when dealing with large data sets (>100 observations), when stem and leaf plots become tedious to construct. A histogram can also help detect any unusual observations (outliers), or any gaps in the data set. Compare bar chart.
Stem and Leaf Plot
A stem and leaf plot is a way of summarising a set of data measured on an interval scale. It is often used in exploratory data analysis to illustrate the major features of the distribution of the data in a convenient and easily drawn form. A stem and leaf plot is similar to a histogram but is usually a more informative display for relatively small data sets (<100 data points). It provides a table as well as a picture of the data and from it we can readily write down the data in order of magnitude, which is useful for many statistical procedures, e.g. in the skinfold thickness example below: We can compare more than one data set by the use of multiple stem and leaf plots. By using a back-to-back stem and leaf plot, we are able to compare the same characteristic in two different groups, for example, pulse rate after exercise of smokers and non-smokers.
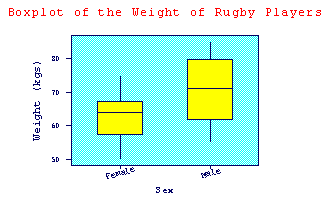
Box and Whisker Plot (or Boxplot)
A box and whisker plot is a way of summarising a set of data measured on an interval scale. It is often used in exploratory data analysis. It is a type of graph which is used to show the shape of the distribution, its central value, and variability. The picture produced consists of the most extreme values in the data set (maximum and minimum values), the lower and upper quartiles, and the median. A box plot (as it is often called) is especially helpful for indicating whether a distribution is skewed and whether there are any unusual observations (outliers) in the data set. Box and whisker plots are also very useful when large numbers of observations are involved and when two or more data sets are being compared. See also 5-Number Summary.
5-Number Summary
A 5-number summary is especially useful when we have so many data that it is sufficient to present a summary of the data rather than the whole data set. It consists of 5 values: the most extreme values in the data set (maximum and minimum values), the lower and upper quartiles, and the median. A 5-number summary can be represented in a diagram known as a box and whisker plot. In cases where we have more than one data set to analyse, a 5-number summary is constructed for each, with corresponding multiple box and whisker plots.
Outlier
An outlier is an observation in a data set which is far removed in value from the others in the data set. It is an unusually large or an unusually small value compared to the others. An outlier might be the result of an error in measurement, in which case it will distort the interpretation of the data, having undue influence on many summary statistics, for example, the mean. If an outlier is a genuine result, it is important because it might indicate an extreme of behaviour of the process under study. For this reason, all outliers must be examined carefully before embarking on any formal analysis. Outliers should not routinely be removed without further justification.
Symmetry
Symmetry is implied when data values are distributed in the same way above and below the middle of the sample. Symmetrical data sets:
Many standard statistical techniques are appropriate only for a symmetric distributional form. For this reason, attempts are often made to transform skew-symmetric data so that they become roughly symmetric.
Skewness
Skewness is defined as asymmetry in the distribution of the sample data values. Values on one side of the distribution tend to be further from the 'middle' than values on the other side. For skewed data, the usual measures of location will give different values, for example, mode<median<mean would indicate positive (or right) skewness. Positive (or right) skewness is more common than negative (or left) skewness. If there is evidence of skewness in the data, we can apply transformations, for example, taking logarithms of positive skew data. Compare symmetry.
Transformation to Normality
If there is evidence of marked non-normality then we may be able to remedy this by applying suitable transformations. The more commonly used transformations which are appropriate for data which are skewed to the right with increasing strength (positive skew) are 1/x, log(x) and sqrt(x), where the x's are the data values. The more commonly used transformations which are appropriate for data which are skewed to the left with increasing strength (negative skew) are squaring, cubing, and exp(x).
Scatter Plot
A scatterplot is a useful summary of a set of bivariate data (two variables), usually drawn before working out a linear correlation coefficient or fitting a regression line. It gives a good visual picture of the relationship between the two variables, and aids the interpretation of the correlation coefficient or regression model. Each unit contributes one point to the scatterplot, on which points are plotted but not joined. The resulting pattern indicates the type and strength of the relationship between the two variables. Illustrations
A scatterplot will also show up a non-linear relationship between the two variables and whether or not there exist any outliers in the data. More information can be added to a two-dimensional scatterplot - for example, we might label points with a code to indicate the level of a third variable. If we are dealing with many variables in a data set, a way of presenting all possible scatter plots of two variables at a time is in a scatterplot matrix.
Sample Mean
The sample mean is an estimator available for estimating the population mean . It is a measure of location, commonly called the average, often symbolised Its value depends equally on all of the data which may include outliers. It may not appear representative of the central region for skewed data sets. It is especially useful as being representative of the whole sample for use in subsequent calculations.
See also expected value.
Median
The median is the value halfway through the ordered data set, below and above which there lies an equal number of data values. It is generally a good descriptive measure of the location which works well for skewed data, or data with outliers. The median is the 0.5 quantile.
Mode
The mode is the most frequently occurring value in a set of discrete data. There can be more than one mode if two or more values are equally common.
Dispersion
The data values in a sample are not all the same. This variation between values is called dispersion. When the dispersion is large, the values are widely scattered; when it is small they are tightly clustered. The width of diagrams such as dot plots, box plots, stem and leaf plots is greater for samples with more dispersion and vice versa. There are several measures of dispersion, the most common being the standard deviation. These measures indicate to what degree the individual observations of a data set are dispersed or 'spread out' around their mean. In manufacturing or measurement, high precision is associated with low dispersion.
Range
The range of a sample (or a data set) is a measure of the spread or the dispersion of the observations. It is the difference between the largest and the smallest observed value of some quantitative characteristic and is very easy to calculate. A great deal of information is ignored when computing the range since only the largest and the smallest data values are considered; the remaining data are ignored. The range value of a data set is greatly influenced by the presence of just one unusually large or small value in the sample (outlier). Examples
Inter-Quartile Range (IQR)
The inter-quartile range is a measure of the spread of or dispersion within a data set. It is calculated by taking the difference between the upper and the lower quartiles. For example:
The IQR is the width of an interval which contains the middle 50% of the sample, so it is smaller than the range and its value is less affected by outliers.
Quantile
Quantiles are a set of 'cut points' that divide a sample of data into groups containing (as far as possible) equal numbers of observations. Examples of quantiles include quartile, quintile, percentile.
Percentile
Percentiles are values that divide a sample of data into one hundred groups containing (as far as possible) equal numbers of observations. For example, 30% of the data values lie below the 30th percentile. See quantile.
Quartile
Quartiles are values that divide a sample of data into four groups containing (as far as possible) equal numbers of observations. A data set has three quartiles. References to quartiles often relate to just the outer two, the upper and the lower quartiles; the second quartile being equal to the median. The lower quartile is the data value a quarter way up through the ordered data set; the upper quartile is the data value a quarter way down through the ordered data set.
See quantile.
Quintile
Quintiles are values that divide a sample of data into five groups containing (as far as possible) equal numbers of observations. See quantile.
Sample Variance
Sample variance is a measure of the spread of or dispersion within a set of sample data.
See also variance.
Standard Deviation
Standard deviation is a measure of the spread or dispersion of a set of data.
The more widely the values are spread out, the larger the standard deviation. For example, say we have two separate lists of exam results from a class of 30 students; one ranges from 31% to 98%, the other from 82% to 93%, then the standard deviation would be larger for the results of the first exam.
Coefficient of Variation
The coefficient of variation measures the spread of a set of data as a proportion of its mean. It is often expressed as a percentage.
There is an equivalent definition for the coefficient of variation of a population, which is based on the expected value and the standard deviation of a random variable.
|



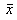 .
.